



LxMLS - Lab Guide
July 13, 2020























































































Estude fácil! Tem muito documento disponível na Docsity

Ganhe pontos ajudando outros esrudantes ou compre um plano Premium

Prepare-se para as provas
Estude fácil! Tem muito documento disponível na Docsity
Prepare-se para as provas com trabalhos de outros alunos como você, aqui na Docsity
Encontra documentos específicos para os exames da tua universidade
Prepare-se com as videoaulas e exercícios resolvidos criados a partir da grade da sua Universidade
Responda perguntas de provas passadas e avalie sua preparação.
Ganhe pontos para baixar
Ganhe pontos ajudando outros esrudantes ou compre um plano Premium
Ver ver ver ver ver ver ver ver ver ver ver ver ver Ver ver ver ver ver ver ver ver ver ver ver ver ver Ver ver ver ver ver ver ver ver ver ver ver ver ver Ver ver ver ver ver ver ver ver ver ver ver ver ver Ver ver ver ver ver ver ver ver ver ver ver ver ver Ver ver ver ver ver ver ver ver ver ver ver ver verVer ver ver ver ver ver ver ver ver ver ver ver ver
Tipologia: Manuais, Projetos, Pesquisas
1 / 105

Esta página não é visível na pré-visualização
Não perca as partes importantes!
In this class we will introduce several fundamental concepts needed further ahead. We start with an introduc- tion to Python, the programming language we will use in the lab sessions, and to Matplotlib and Numpy, two modules for plotting and scientific computing in Python, respectively. Afterwards, we present several notions on probability theory and linear algebra. Finally, we focus on numerical optimization. The goal of this class is to give you the basic knowledge for you to understand the following lectures. We will not enter in too much detail in any of the topics.
If you have decided to use one of our provided desktops, all installation procedures have been carried out. You merely need to go to the lxmls-toolkit-student folder inside your home directory and start working! You may go directly to section 0.3. If you wish to use your own laptop, you will need to install Python, the required Python libraries and download the LXMLS code base. It is important that you do this as soon as possible (before the school starts) to avoid unnecessary delays. Please follow the install instructions.
The code of LxMLS is available online at GitHub. There are two branches of the code: the master branch contains fully functional code. important : The student branch contains the same code with some parts deleted, which you must complete in the following exercises. Download the student code by going to
https://github.com/LxMLS/lxmls-toolkit
and select the student branch in the dropdown menu. This will reload the page to the corresponding branch. Now you just need to click the clone or download button to obtain the lab tools in a zip format:
lxmls-toolkit-student.zip
After this you can unzip the file where you want to work and enter the unzipped folder. This will be the place where you will work.
If you are new to Python the best option right now is the Anaconda platform. You can find installers for Windows, Linux and OSX platforms here
https://www.anaconda.com/download/ https://anaconda.org/pytorch/pytorch
Finally install the LXMLS toolkit symbolically. This will allow you to modify the code and see the changes take place immediately.
An Integrated Development Environment (IDE) includes a text editor and various tools to debug and interpret complex code. Important: As the labs progress you will need an IDE, or at least a good editor and knowledge of pdb/ipdb. This will not be obvious the first days since we will be seeing simpler examples. Easy IDEs to work with Python are PyCharm and Visual Studio Code, but feel free to use the software you feel more comfortable with. PyCharm and other well known IDEs like Spyder are provided with the Anaconda installation. Aside of an IDE, you will need an interactive command line to run commands. This is very useful to explore variables and functions and quickly debug the exercises. For the most complex exercises you will still need an IDE to modify particular segments of the provided code. As interactive command line we recommend the Jupyter notebook. This also comes installed with Anaconda and is part of the pip-installed packages. The Jupyter notebook is described in the next section. In case you run into problems or you feel uncomfortable with the Jupyter notebook you can use the simpler iPython command line.
Jupyter is a good choice for writing Python code. It is an interactive computational environment for data sci- ence and scientific computing, where you can combine code execution, rich text, mathematics, plots and rich media. The Jupyter Notebook is a web application that allows you to create and share documents, which con- tains live code, equations, visualizations and explanatory text. It is very popular in the areas of data cleaning and transformation, numerical simulation, statistical modeling, machine learning and so on. It supports more than 40 programming languages, including all those popular ones used in Data Science such as Python, R, and Scala. It can also produce many different types of output such as images, videos, LaTex and JavaScript. More over with its interactive widgets, you can manipulate and visualize data in real time. The main features and advantages using the Jupyter Notebook are the following:
The basic commands you should know are
Esc Enter command mode Enter Enter edit mode up/down Change between cells Ctrl + Enter Runs code on selected cell Shift + Enter Runs code on selected cell, jumps to next cell restart button Deletes all variables (useful for troubleshooting)
Table 1: Basic Jupyter commands
A more detailed user guide can be found here:
http://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/index.html
0.3 Solving the Exercises
In the student branch we provide the solve.py script. This can be used to solve the exercises of each day, e.g.,
python ./solve.py linear_classifiers
where the solvable days are: linear classifiers, sequence models, structure predictors, non-linear classifiers, non-linear sequence models, reinforcement learning. You can also undo the solving of an exercise by using
python ./solve.py --undo linear_classifiers
Note that this script just downloads the master or student versions of certain files from the GitHub repos- itory. It needs an Internet connection. Since some exercises require you to have the exercises of the previous days completed, the monitors may ask you to use this function. Important: Remember to save your own version of the code, otherwise it will be overwritten!
0.4 Python
Pre-requisites
At this point you should have installed the needed packages. You need also to feel comfortable with an IDE to edit code and an interactive command line. See previous sections for the details. Your work folder will be
lxmls-toolkit-student
from there, start your interactive command line of choosing, e.g.,
jupyter-notebook
and proceed with the following sections.
Running Python code
We will start by creating and running a dummy program in Python which simply prints the “Hello World!” message to the standard output (this is usually the first program you code when learning a new programming language). There are two main ways in which you can run code in Python:
From a file – Create a file named yourfile.py and write your program in it, using the IDE of your choice, e.g., PyCharm:
print ('Hello World!')
After saving and closing the file, you can run your code by using the run functionality in your IDE. If you wish to run from a command line instead do
python yourfile.py
This will run the program and display the message “Hello World!”. After that, the control will return to the command line or IDE.
In the interactive command line – Start your preferred interactive command line, e.g., Jupyter-notebook. There, you can run Python code by simply writing it and pressing enter (ctr+enter in Jupyter).
In[]: print ("Hello, World!") Out[]: Hello, World!
For Python 3, the division is considered float point, so the operation (3 / 5) or (3 / 5.0) is always 0.6. Also, notice that the symbol (^) ** is used as exponentation operator, unlike other major languages which use the symbol ˆ. In fact, the ˆ symbol has a different meaning in Python (bitwise XOR) so, in the beginning, be sure to double-check your code if it uses exponentiation and it is giving unexpected results.
Data Structures
In Python, you can create lists of items with the following syntax:
countries = ['Portugal','Spain','United Kingdom']
A string should be surrounded by either apostrophes (’) or quotes (“). You can access a list with the following:
Exercise 0.1 Use L[i:j] to return the countries in the Iberian Peninsula.
Loops and Indentation
A loop allows a section of code to be repeated a certain number of times, until a stop condition is reached. For instance, when the list you are iterating over has reached its end or when a variable has reached a certain value (in this case, you should not forget to update the value of that variable inside the code of the loop). In Python you have while and for loop statements. The following two example programs output exactly the same using both statements: the even numbers from 2 to 8.
i = 2 while i < 10: print (i) i += 2
for i in range (2,10,2): print (i)
You can copy and run this in Jupyter. Alternatively you can write this into your yourfile.py file and run it. Do you notice something? It is possible that the code did not act as expected or maybe an error message popped up. This brings us to an important aspect of Python: indentation. Indentation is the number of blank spaces at the leftmost of each command. This is how Python differentiates between blocks of commands inside and outside of a statement, e.g., while or for. All commands within a statement have the same number of blank spaces at their leftmost. For instance, consider the following code:
a= while a <= 3: print (a) a += 1
and its output:
1 2 3
Exercise 0.2 Can you then predict the output of the following code?:
a= while a <= 3: print (a) a += 1
Bear in mind that indentation is often the main source of errors when starting to work with Python. Try to get used to it as quickly as possible. It is also recommendable to use a text editor that can display all characters e.g. blank space, tabs, since these characters can be visually similar but are considered different by Python. One of the most common mistakes by newcomers to Python is to have their files indented with spaces on some lines and with tabs on other lines. Visually it might appear that all lines have proper indentation, but you will get an IndentationError message if you try it. The recommended^1 way is to use 4 spaces for each indentation level.
Control Flow
The if statement allows to control the flow of your program. The next program outputs a greeting that depends on the time of the day.
hour = 16 if hour < 12: print ('Good morning!') elif hour >= 12 and hour < 20: print ('Good afternoon!') else : print ('Good evening!')
Functions
A function is a block of code that can be reused to perform a similar action. The following is a function in Python.
def greet (hour): if hour < 12: print ('Good morning!') elif hour >= 12 and hour < 20: print ('Good afternoon!') else : print ('Good evening!')
You can write this command into Jupyter directly or write it into a file which you then run in Jupyter. Once you do this the function will be available for you to use. Call the function greet with different hours of the day (for example, type greet(16)) and see that the program will greet you accordingly.
Exercise 0.3 Note that the previous code allows the hour to be less than 0 or more than 24. Change the code in order to indicate that the hour given as input is invalid. Your output should be something like:
greet(50) Invalid hour: it should be between 0 and 24. greet(-5) Invalid hour: it should be between 0 and 24.
(^1) The PEP8 document (www.python.org/dev/peps/pep-0008) is the official coding style guide for the Python language.
(h)elp Starts the help menu (p)rint Prints a variable (p)retty(p)rint Prints a variable, with line break (useful for lists) (n)ext line Jumps to next line (s)tep Jumps inside of the function we stopped at c(ont(inue)) Continues execution until finding breakpoint or finishing (r)eturn Continues execution until current function returns b(reak) n Sets a breakpoint in in line n b(reak) n, condition Sets a conditional breakpoint in in line n l(ist) [n], [m] Prints 11 lines around current line. Optionally starting in line n or between lines n, m w(here) Shows which function called the function we are in, and upwards (stack) u(p) Goes one level up the stack (frame of the function that called the function we are on) d(down) Goes one level down the stack blank Repeat the last command expression Executes the python expression as if it was in current frame
Table 2: Basic pdb/ipdb commands, parentheses indicates abbreviation
pdb> n > ./lxmls-toolkit/yourfile.py(8)greet() 7 import pdb; pdb.set_trace() ----> 8 print ('Good evening!')
Now we can inspect the variable hour using the p(retty)p(rint) option
pdb> pp hour 50
From here we could keep advancing with the n(ext) option or set a b(reak) point and type c(ontinue) to jump to a new position. We could also execute any python expression which is valid in the current frame (the function we stopped at). This is particularly useful to find out why code crashes, as we can try different alternatives without the need to restart the code again.
Occasionally, a syntactically correct code statement may produce an error when an attempt is made to execute it. These kind of errors are called exceptions in Python. For example, try executing the following:
10/
A ZeroDivisionError exception was raised, and no output was returned. Exceptions can also be forced to occur by the programmer, with customized error messages 3.
raise ValueError ("Invalid input value.")
Exercise 0.4 Rewrite the code in Exercise 0.3 in order to raise a ValueError exception when the hour is less than 0 or more than 24.
Handling of exceptions is made with the try statement:
(^3) For a complete list of built-in exceptions, see http://docs.python.org/3/library/exceptions.html
while True : try : x = int ( input ("Please enter a number: ")) break except ValueError : print ("Oops! That was no valid number. Try again...")
It works by first executing the try clause. If no exception occurs, the except clause is skipped; if an exception does occur, and if its type matches the exception named in the except keyword, the except clause is executed; otherwise, the exception is raised and execution is aborted (if it is not caught by outer try statements).
Extending basic Functionalities with Modules
In Python you can load new functionalities into the language by using the import, from and as keywords. For example, we can load the numpy module as
import numpy as np
Then we can run the following on the Jupyter command line:
np.var? np.random.normal?
The import will make the numpy tools available through the alias np. This shorter alias prevents the code from getting too long if we load lots of modules. The first command will display the help for the method numpy.var using the previously commented symbol ?. Note that in order to display the help you need the full name of the function including the module name or alias. Modules have also submodules that can be accessed the same way, as shown in the second example.
Organizing your Code with your own modules
Creating you own modules is extremely simple. you can for example create the file in your work directory
my_tools.py
and store there the following code
def my_print ( input ): print ( input )
From Jupyter you can now import and use this tool as
import my_tools my_tools.my_print("This works!")
Important : When you modify a module, you need to reload the notebook page for the changes to take effect. Autoreload is set by default in the schools notebooks. for the latter. Other ways of importing one or all the tools from a module are
from my_tools import my_print # my_print directly accesible in code from my_tools import (^) * # will make all functions in my_tools accessible
However, this makes reloading the module more complicated. You can also store tools ind different folders. For example, if you store the previous example in the folder
Numpy^5 is a library for scientific computing with Python.
Multidimensional Arrays
The main object of numpy is the multidimensional array. A multidimensional array is a table with all elements of the same type and can have several dimensions. Numpy provides various functions to access and manipu- late multidimensional arrays. In one dimensional arrays, you can index, slice, and iterate as you can with lists. In a two dimensional array M, you can perform these operations along several dimensions.
Again, as it happened with the lists, the first item of every column and every row has index 0.
import numpy as np A = np.array([ [1,2,3], [2,3,4], [4,5,6]])
A[0,:] # This is [1,2,3] A[0] # This is [1,2,3] as well
A[:,0] # this is [1,2,4]
A[1:,0] # This is [ 2, 4 ]. Why?
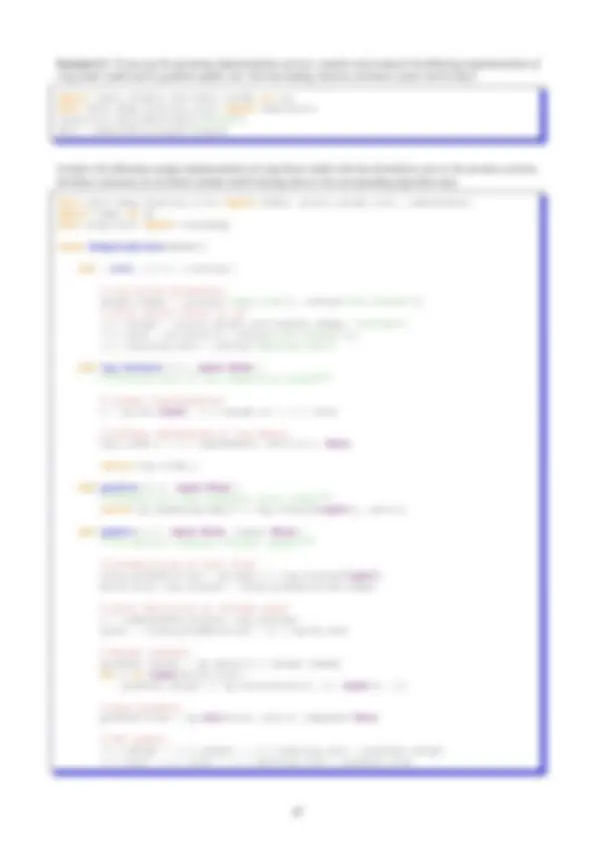
Mathematical Operations
There are many helpful functions in numpy. For basic mathematical operations, we have np.log, np.exp, np.cos,... with the expected meaning. These operate both on single arguments and on arrays (where they will behave element wise).
import matplotlib.pyplot as plt import numpy as np
X = np.linspace(0, (^4) * np.pi, 1000) C = np.cos(X) S = np.sin(X)
plt.plot(X, C) plt.plot(X, S)
Other functions take a whole array and compute a single value from it. For example, np.sum, np.mean,... These are available as both free functions and as methods on arrays.
import numpy as np
A = np.arange(100)
print (np.mean(A)) print (A.mean())
(^5) http://www.numpy.org/
C = np.cos(A) print (C.ptp())
Exercise 0.6 Run the above example and lookup the ptp function/method (use the? functionality in Jupyter).
Exercise 0.7 Consider the following approximation to compute an integral
∫ (^1)
0
f (x)dx ≈
999 ∑ i= 0
f (i/1000) 1000
Use numpy to implement this for f (x) = x^2. You should not need to use any loops. Note that integer division in Python 2.x returns the floor division (use floats – e.g. 5.0/2.0 – to obtain rationals). The exact value is 1/3. How close is the approximation?
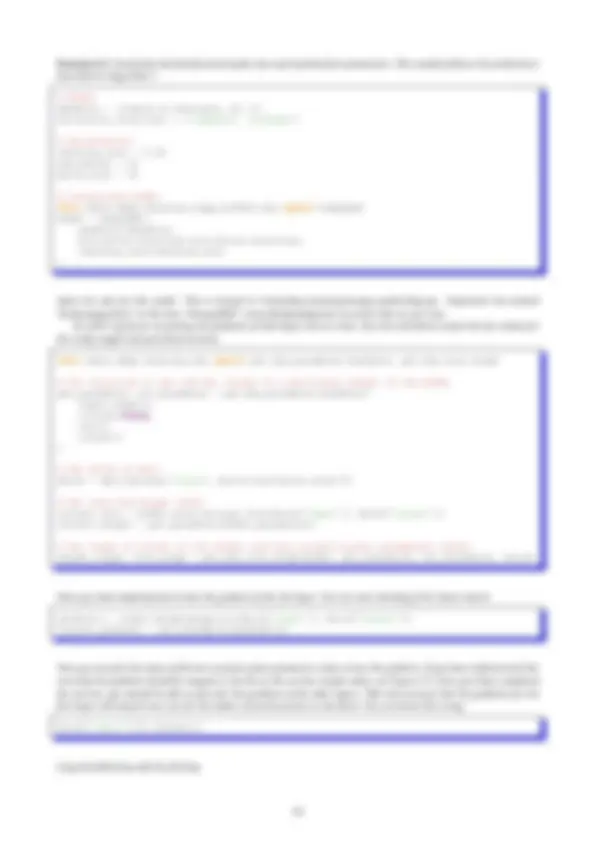
0.5 Essential Linear Algebra
Linear Algebra provides a compact way of representing and operating on sets of linear equations. { 4 x 1 − 5 x 2 = − 13 − 2 x 1 + 3 x 2 = 9 This is a system of linear equations in 2 variables. In matrix notation we can write the system more com- pactly as Ax = b
with
A =
, b =
We use the following notation:
x =
x 1 x 2 .. . xn
Exercise 0.8 In the rest of the school we will represent both matrices and vectors as numpy arrays. You can create arrays in different ways, one possible way is to create an array of zeros.
import numpy as np m = 3 n = 2 a = np.zeros([m,n]) print (a) [[ 0. 0.] [ 0. 0.] [ 0. 0.]]
x T^ y ∈ R =
x 1 x 2... xn
y 1 y 2 .. . yn
n ∑ i= 1
xiyi.
a = np.array([1,2]) b = np.array([1,1]) np.dot(a,b)
xy T^ ∈ R m×n^ =
x 1 x 2 .. . xm
y 1 y 2... yn
x 1 y 1 x 1 y 2... x 1 yn x 2 y 1 x 2 y 2... x 2 yn .. .
xmy 1 xmy 2... xmyn
np.outer(a,b) array([[1, 1], [2, 2]])
1 i = j 0 i 6 = j It has the property that for all A ∈ R n×n, AI = A = IA.
I = np.eye(2) x = np.array([2.3, 3.4])
print (I) print (np.dot(I,x))
[[ 1., 0.], [ 0., 1.]] [2.3, 3.4]
A = np.array([ [1, 2], [3, 4] ]) print (A.T)
n ∑ i= 1
Aii
The norm of a vector is informally the measure of the “length” of the vector. The commonly used Euclidean or ` 2 norm is given by
‖ x ‖ 2 =
n ∑ i= 1
x^2 i.
‖ x ‖p =
( (^) n ∑ i= 1
|xi|p
)1/p .
Note: ` 1 norm :^ ‖ x ‖ 1 =^
n ∑ i= 1
|xi| `∞ norm : ‖ x ‖∞ = max i
|xi| (^).
A set of vectors { x 1 , x 2 ,... , x n} ⊂ R m^ is said to be (linearly) independent if no vector can be represented as a linear combination of the remaining vectors. Conversely, if one vector belonging to the set can be represented as a linear combination of the remaining vectors, then the vectors are said to be linearly dependent. That is, if
x j = (^) ∑ i 6 =j
α i x i
for some j ∈ {1,... , n} and some scalar values α 1 ,... , α i− 1 , α i+ 1 ,... , α n ∈ R.
U T^ U = I = UU T^.
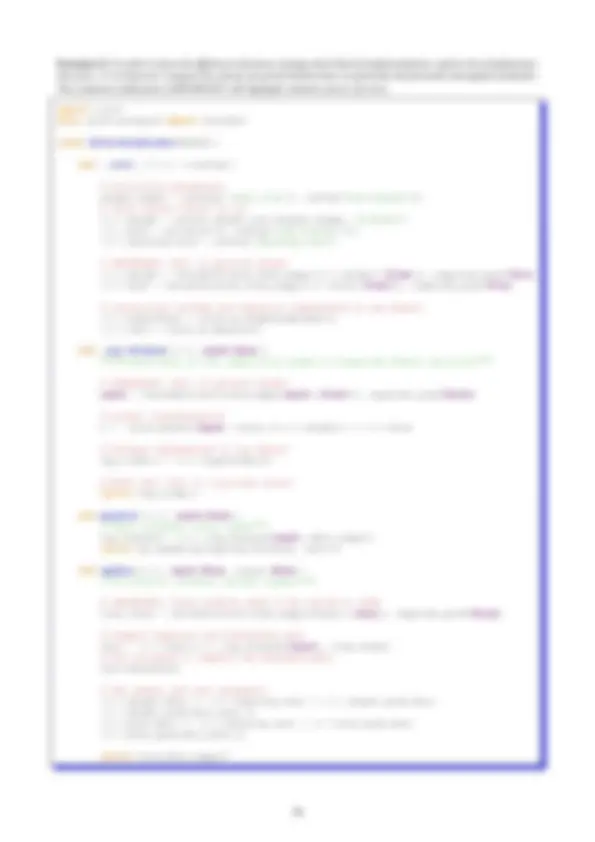
0.6 Probability Theory
Probability is the most used mathematical language for quantifying uncertainty. The sample space X is the set of possible outcomes of an experiment. Events are subsets of X.
Example 0.1 (discrete space) Let H denote “heads” and T denote “tails.” If we toss a coin twice, then X = {HH, HT, TH, TT}. The event that the first toss is heads is A = {HH, HT}.
A sample space can also be continuous (eg., X = R ). The union of events A and B is defined as A
⋃ B =
{ ω ∈ X | ω ∈ A ∨ ω ∈ B}. If A 1 ,.. ., An is a sequence of sets then
⋃n i= 1
Ai = { ω ∈ X | ω ∈ Ai for at least one i}.
We say that A 1 ,.. ., An are disjoint or mutually exclusive if Ai ∩ Aj = ∅ whenever i 6 = j.
We want to assign a real number P(A) to every event A, called the probability of A. We also call P a probability distribution or probability measure.
parameter (usually trained from data) and posterior is the updated belief about the parameters.
A random variable is a mapping X : X → R that assigns a real number X( ω ) to each outcome ω. Given a ran- dom variable X, an important function called the cumulative distributive function (or distribution function ) is defined as:
Definition 0.3 The cumulative distribution function CDF FX : R → [0, 1] of a random variable X is defined by FX (x) = P(X ≤ x).
The CDF is important because it captures the complete information about the random variable. The CDF is right-continuous, non-decreasing and is normalized (limx→−∞ F(x) = 0 and limx→∞ F(x) = 1).
Example 0.2 (discrete CDF) Flip a fair coin twice and let X be the random variable indicating the number of heads. Then P(X = 0 ) = P(X = 2 ) = 1/4 and P(X = 1 ) = 1/2. The distribution function is
FX (x) =
0 x < 0 1/4 0 ≤ x < 1 3/4 1 ≤ x < 2 1 x ≥ 2.
Definition 0.4 X is discrete if it takes countable many values {x 1 , x 2 ,.. .}. We define the probability function or probability mass function for X by fX (x) = P(X = x).
Definition 0.5 A random variable X is continuous if there exists a function fX such that fX ≥ 0 for all x, ∫^ ∞ −∞
fX (x)dx = 1 and for every a ≤ b
P(a < X < b) =
∫^ b
a
fX (x)dx. (5)
The function fX is called the probability density function (PDF). We have that
FX (x) =
∫^ x
−∞
fX (t)dt
and fX (x) = F X′ (x) at all points x at which FX is differentiable.
A discussion of a few important distributions and related properties:
The Bernoulli distribution is a discrete probability distribution that takes value 1 with the success probability p and 0 with the failure probability q = 1 − p. A single Bernoulli trial is parametrized with the success probability p, and the input k ∈ {0, 1} (1=success, 0=failure), and can be expressed as
f (k; p) = pkq^1 −k^ = pk( 1 − p)^1 −k
The probability distribution for the number of successes in n Bernoulli trials is called a Binomial distribution , which is also a discrete distribution. The Binomial distribution can be expressed as exactly j successes is
f (j, n; p) =
n j
pjqn−j^ =
n j
pj( 1 − p)n−j
where n is the number of Bernoulli trials with probability p of success on each trial.
The Categorical distribution (often conflated with the Multinomial distribution, in fields like Natural Lan- guage Processing) is another generalization of the Bernoulli distribution, allowing the definition of a set of possible outcomes, rather than simply the events “success” and “failure” defined in the Bernoulli distribution. Considering a set of outcomes indexed from 1 to n, the distribution takes the form of
f (xi; p 1 , ..., pn) = pi.
where parameters p 1 , ..., pn is the set with the occurrence probability of each outcome. Note that we must ensure that ∑ni= 1 pi = 1, so we can set pn = 1 − ∑n i=− 11 pi.
The Multinomial distribution is a generalization of the Binomial distribution and the Categorical distribution, since it considers multiple outcomes, as the Categorial distribution, and multiple trials, as in the Binomial distribution. Considering a set of outcomes indexed from 1 to n, the vector [x 1 , ..., xn], where xi indicates the number of times the event with index i occurs, follows the Multinomial distribution
f (x 1 , ..., xn; p 1 , ..., pn) =
n! x 1 !...xn!
px 1 1 ...px nn.
Where parameters p 1 , ..., pn represent the occurrence probability of the respective outcome.
A very important theorem in probability theory is the Central Limit Theorem. The Central Limit Theorem states that, under very general conditions, if we sum a very large number of mutually independent random variables, then the distribution of the sum can be closely approximated by a certain specific continuous density called the normal (or Gaussian) density. The normal density function with parameters μ and σ is defined as follows:
fX (x) =
2 πσ
e−(x− μ )
(^2) /2 σ 2 , − ∞ < x < ∞.
Figure 1: Normal density for two sets of parameter values.
Figure 1 compares a plot of normal density for the cases μ = 0 and σ = 1, and μ = 0 and σ = 2.
Until now we assumed that, for every distribution, the parameters θ are known and are used when we calculate p(x| θ ). There are some cases where the values of the parameters are easy to infer, such as the probability p of