Download Control Hazard Solutions - High Performance Computing - Lecture Slides and more Slides Computer Science in PDF only on Docsity!
High Performance Computing
Lecture 25
2 Control Hazard Solutions
1. Static Branch Prediction
2. Delayed Branching
Design hardware so that control transfer
takes place after a few of the following
instructions
BEQ R1, R2, target
ADD R3, R2, R
Delay slots: following instructions that are
executed whether or not the branch is taken
Stall cycles are avoided if the delay slots
are filled with useful instructions
4
Delayed Branching…Compiler’s Role
When filled from branch target or fall-through, patch-up code may be needed BEQZ R1, target target: ADDI R7, R7, 1 / Branch delay slot LW R8, - 8(R29)
fall through:
5
Delayed Branching…Compiler’s Role
When filled from branch target or fall-through, patch-up code may be needed BEQZ R1, target ADDI R7, R7, 1 / Branch delay slot target: LW R8, - 8(R29)
SUBI R7, R7, 1
fall through:
7 If no instruction can be found…
The compiler must insert an instruction that
does nothing
other than occupying the delay slot, being fetched
and decoded
Example: ADD R0, R0, R
If an instruction that does nothing was included in
the instruction set, it would be called a No-
Operation instruction, or NOP for short
NOP might be included in the assembly language
It has practically the same effect as a STALL
cycle
8 Pipeline and Programming
Consider a simple pipeline with the following
warnings in the ISA manual
1. One load delay slot
2. One branch delay slot
3. 2 instructions after FP arithmetic operation can’t
use the value computed by that instruction
We will think about a specific program, say
vector addition
double A[1024], B[1024];
for (i=0; i<1024; i++) A[i] = A[i] + B[i];
10 Vector Addition Loop Loop: FLOAD F0, 0(R1) FLOAD F2, 0(R2) FADD F4, F0, F FSTORE 0(R1), F ADDI R1, R1, 8 ADDI R2, R2, 8 BLE R1, R3, Loop Loop: FLOAD F0, 0(R1) FLOAD F2, 0(R2) ADDI R1, R1, 8 FADD F4, F0, F ADDI R2, R2, 8 BLE R1, R3, Loop FSTORE - 8(R1), F 11 cycles per iteration 7 cycles per iteration
11 An even faster loop? Loop Unrolling
Idea: Each time through the loop, do the work
of more than one iteration
More instructions to use in reordering
Less instructions executed for loop control
… but program increases in size
13 Agenda
- Program execution: Compilation, Object files, Function call and return, Address space, Data & its representation (4)
- Computer organization: Memory, Registers, Instruction set architecture, Instruction processing (6)
- Virtual memory: Address translation, Paging (4)
- Operating system: Processes, System calls, Process management (6)
- Pipelined processors: Structural, data and control hazards, impact on programming (4)
- Cache memory: Organization, impact on programming (5)
- Program profiling (2)
- File systems: Disk management, Name management, Protection (4)
- Parallel programming: Inter-process communication, Synchronization, Mutual exclusion, Parallel architecture, Programming with message passing using MPI (5)
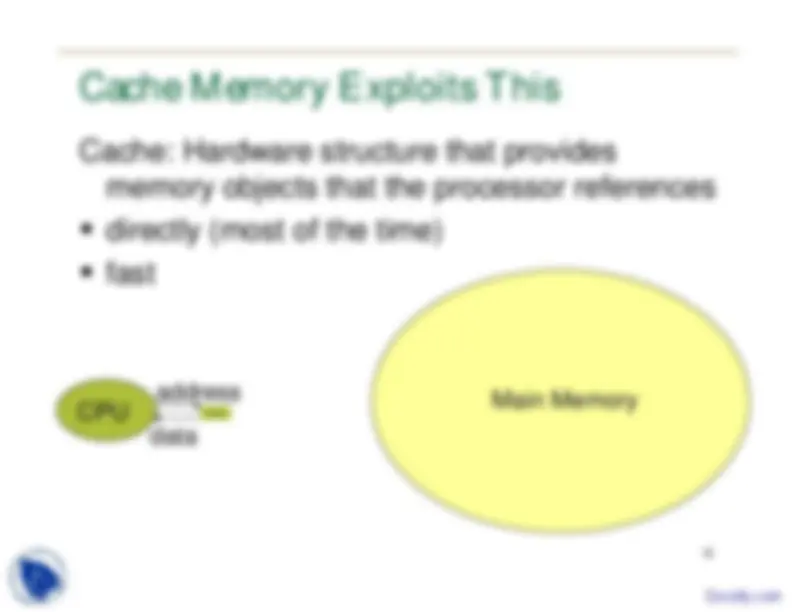
14 Cache Memory; Memory Hierarchy
Recall: In discussing pipeline, we assumed
that memory latency will be hidden so that it
appears to operate at processor speed
Cache Memory: HW that makes this happen
Design principle: Locality of Reference
Temporal locality: least recently used objects are
least likely to be referenced in the near future
Spatial locality: neighbours of recently referenced
locations are likely to be referenced in the near
future
16 Cache Design Cache address **A Fast Memory Do I Have It’? Logic Lookup Logic** Table ofAddresses I Have’ Cache Directory Cache RAM Typical size: 32KB i.e., 1000s of instructions/data items can be stored