



HakimWeatherspoon
CS3410,Spring2012
ComputerScience
CornellUniversity
MIPSPipeline
SeeP&HChapter4.6





























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
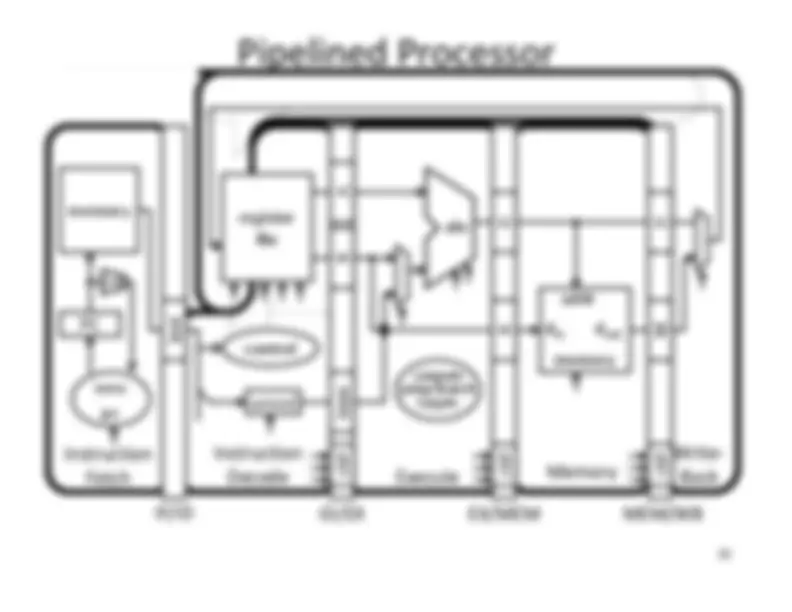
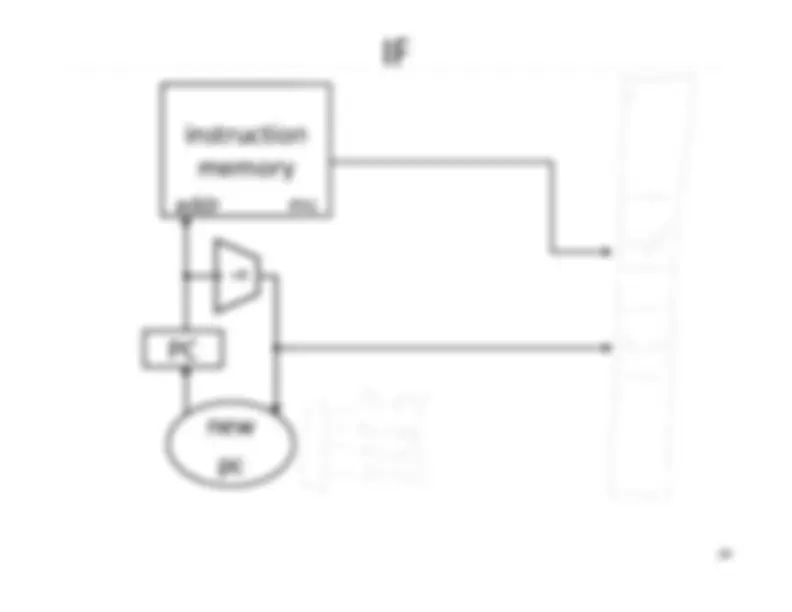
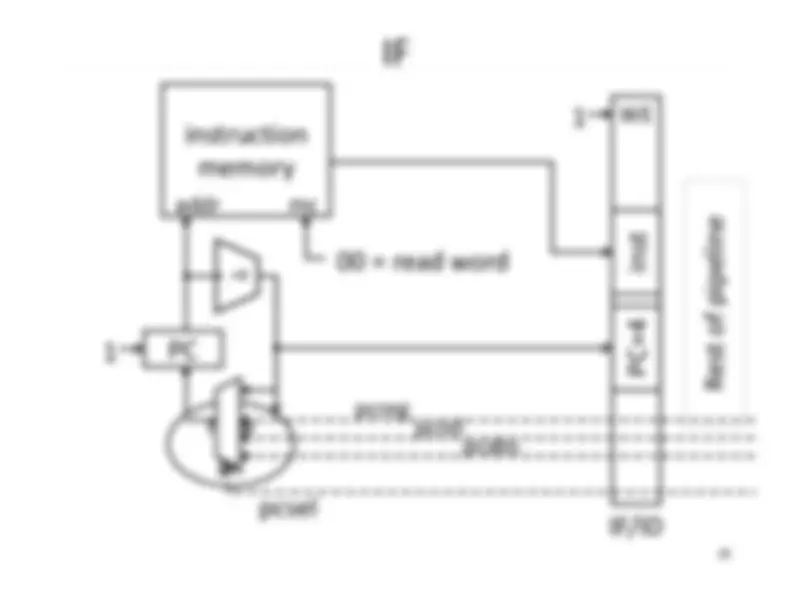
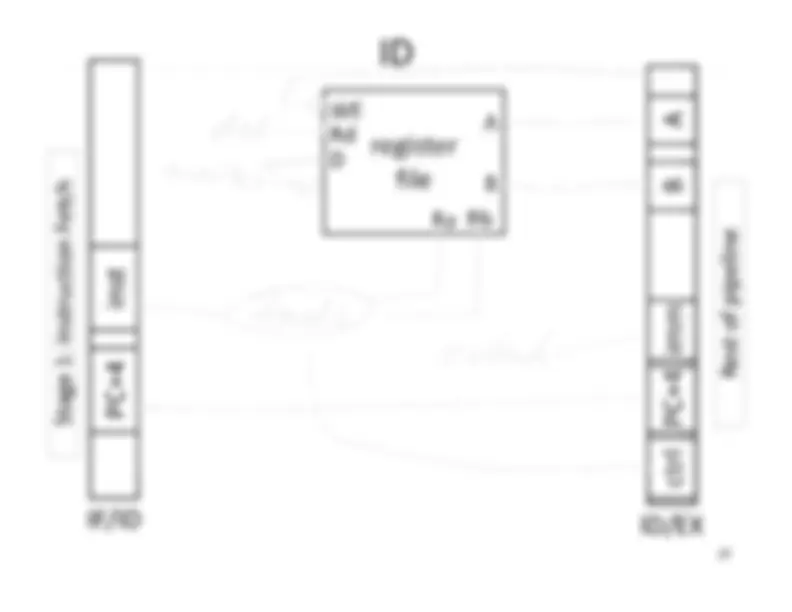
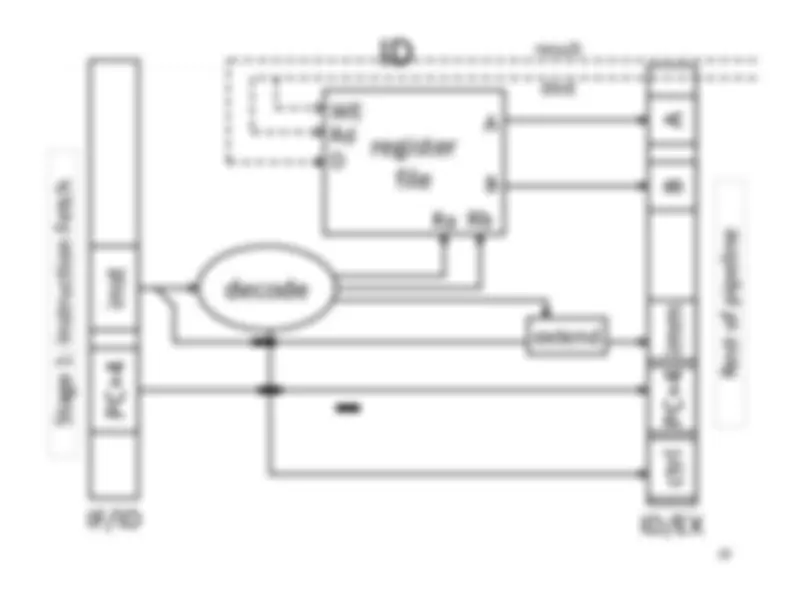
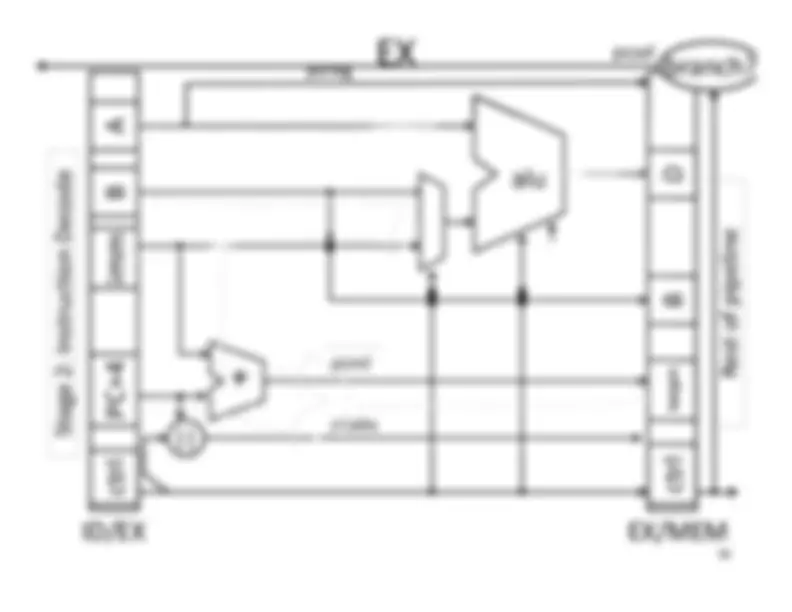
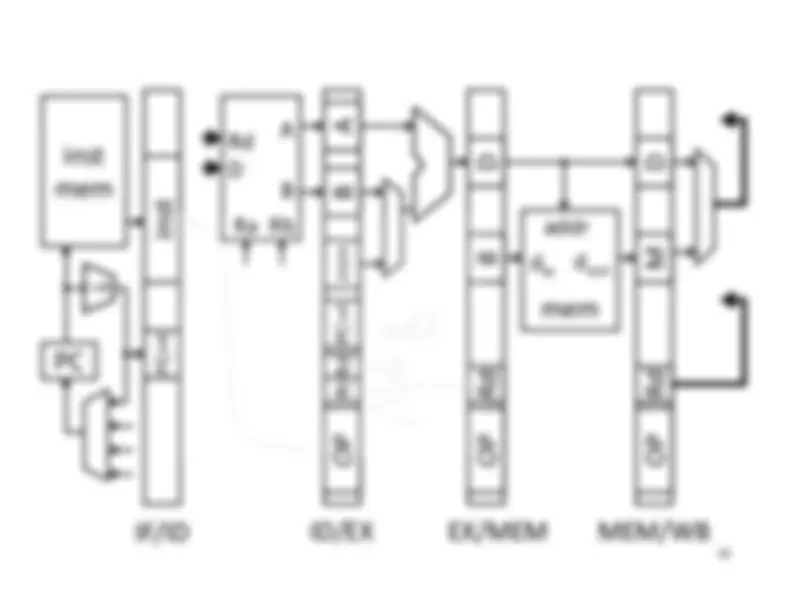
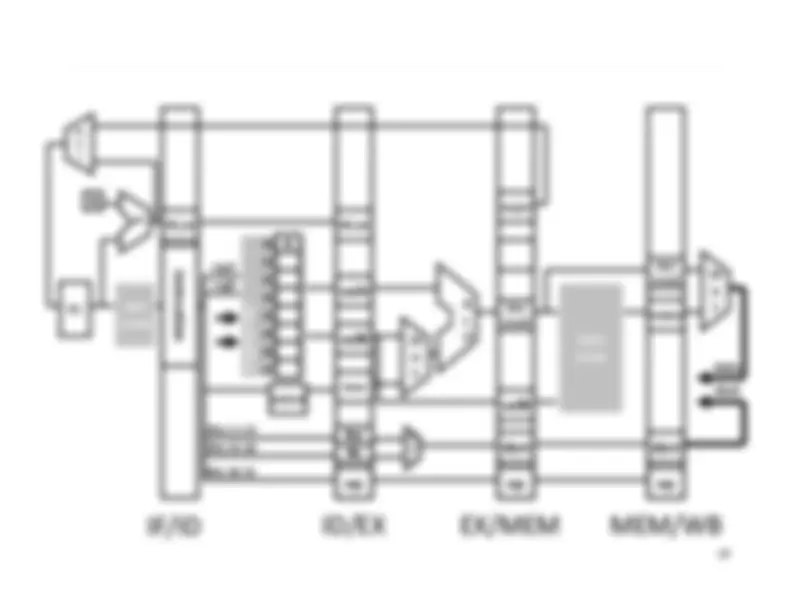
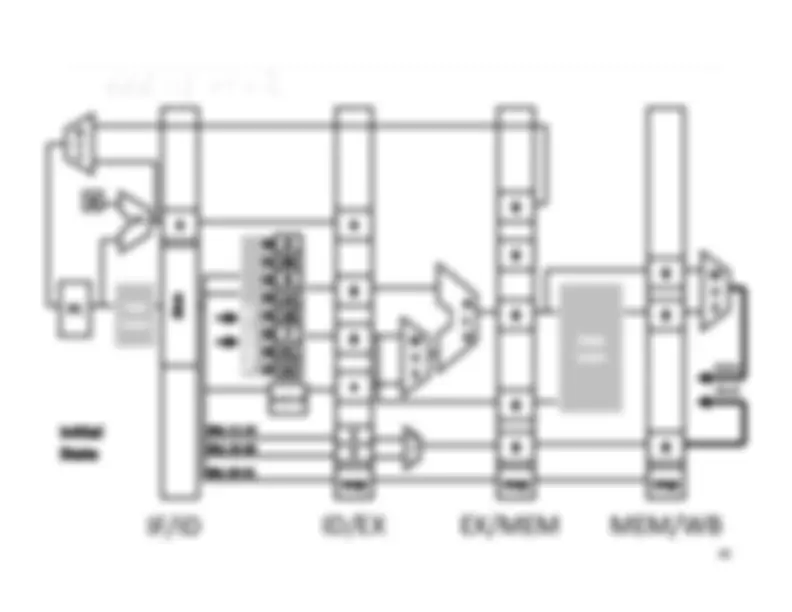
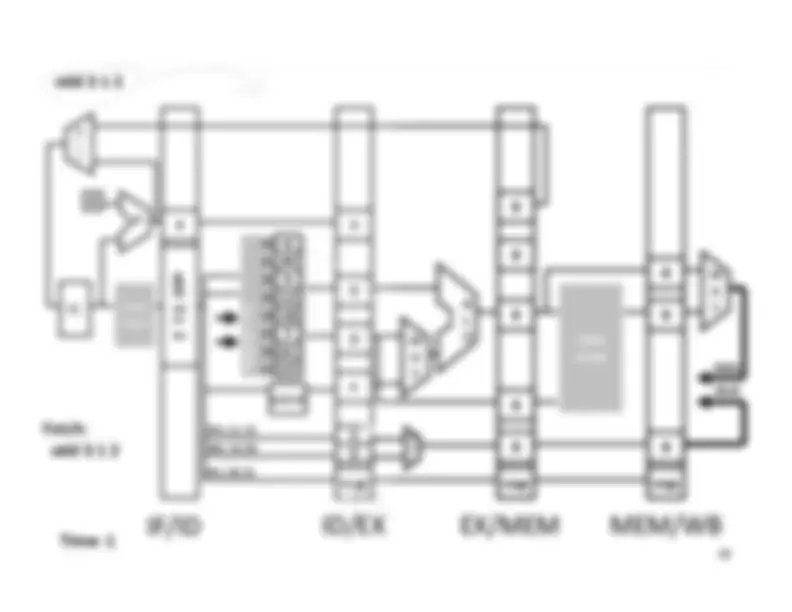
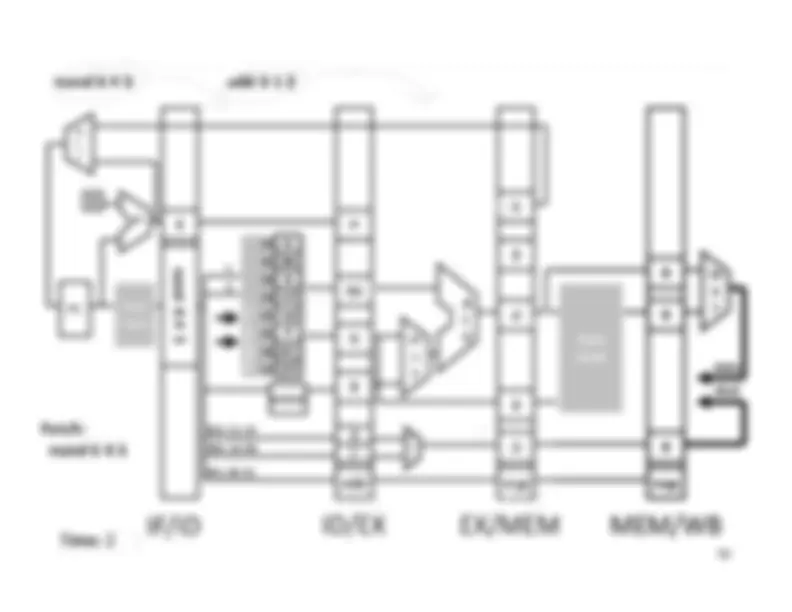
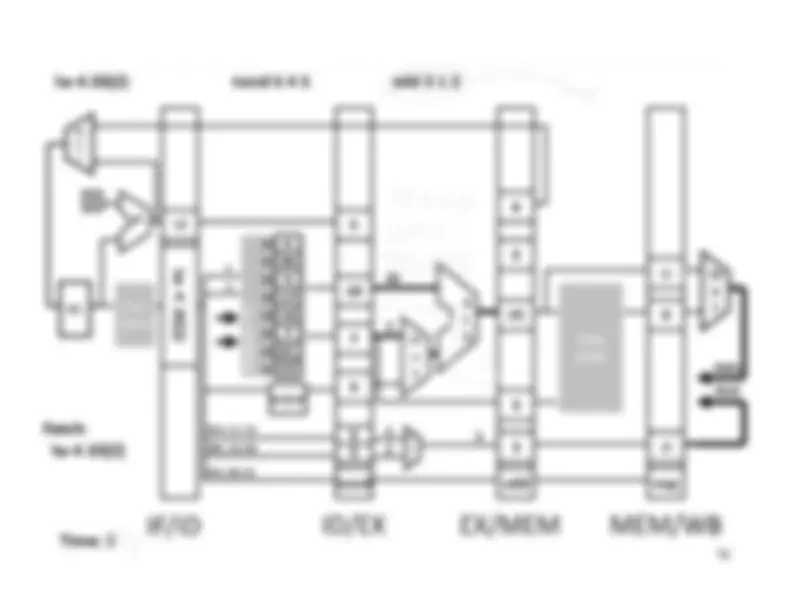
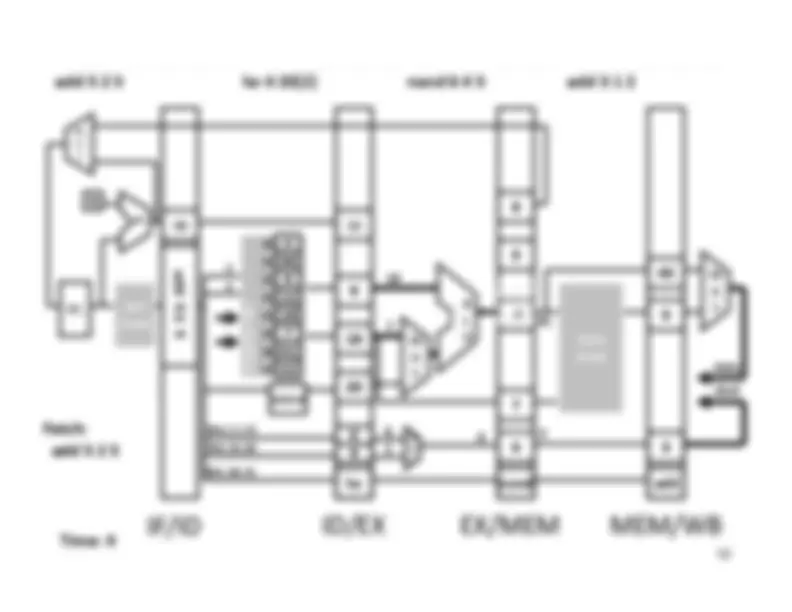
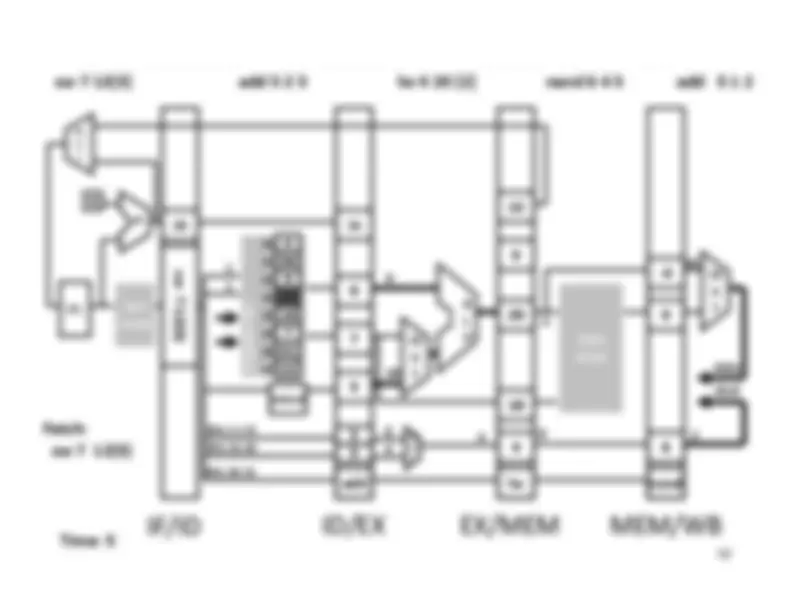
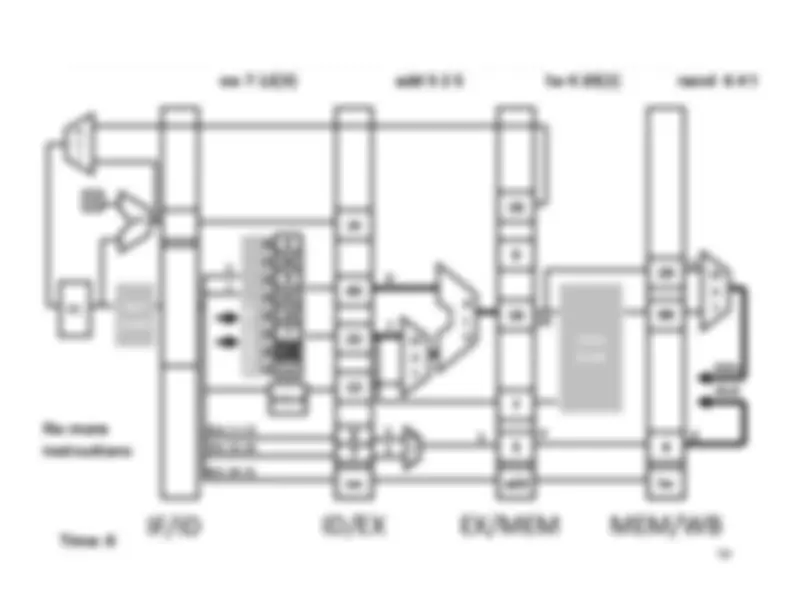
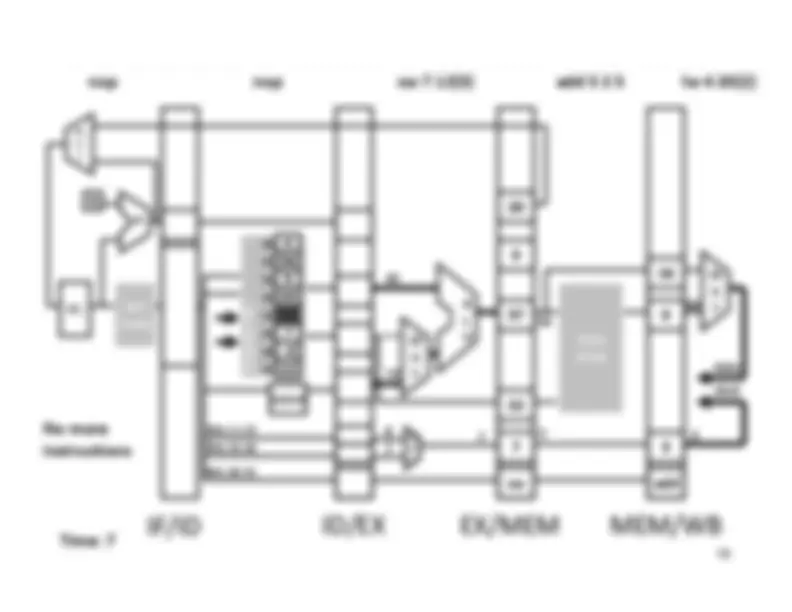
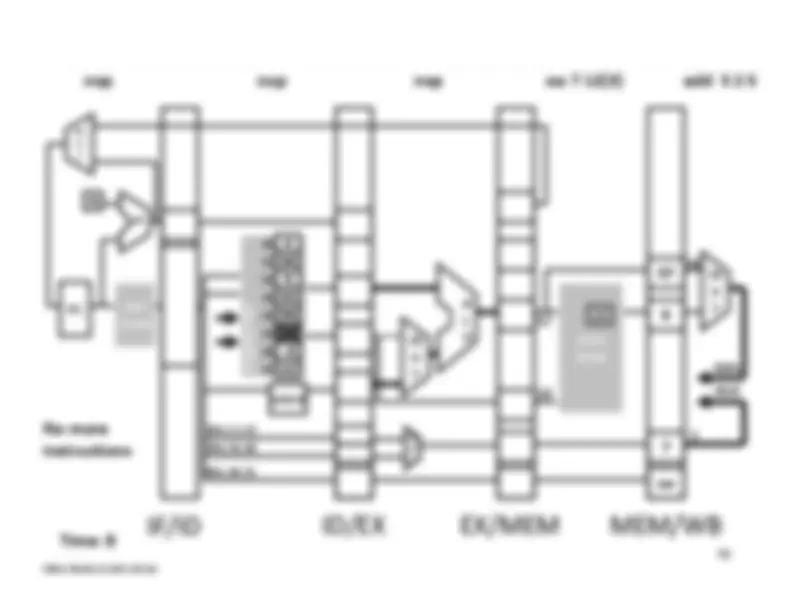
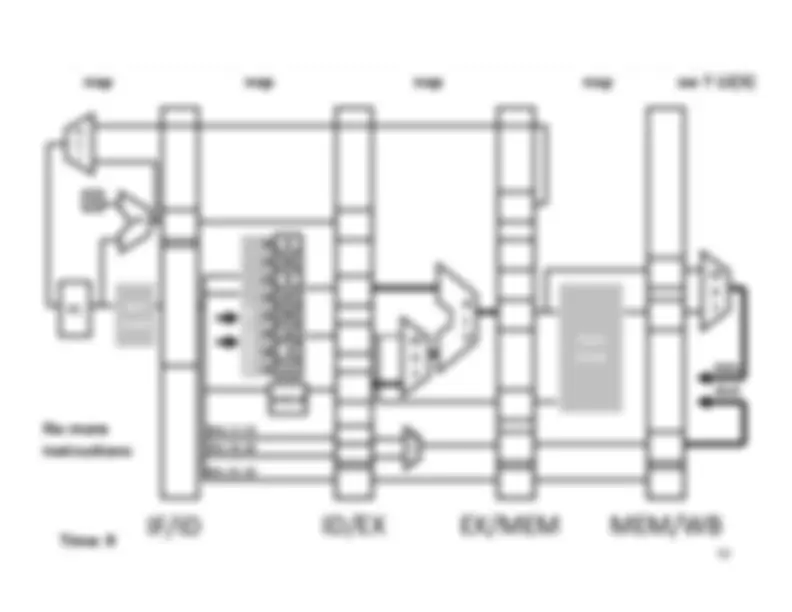
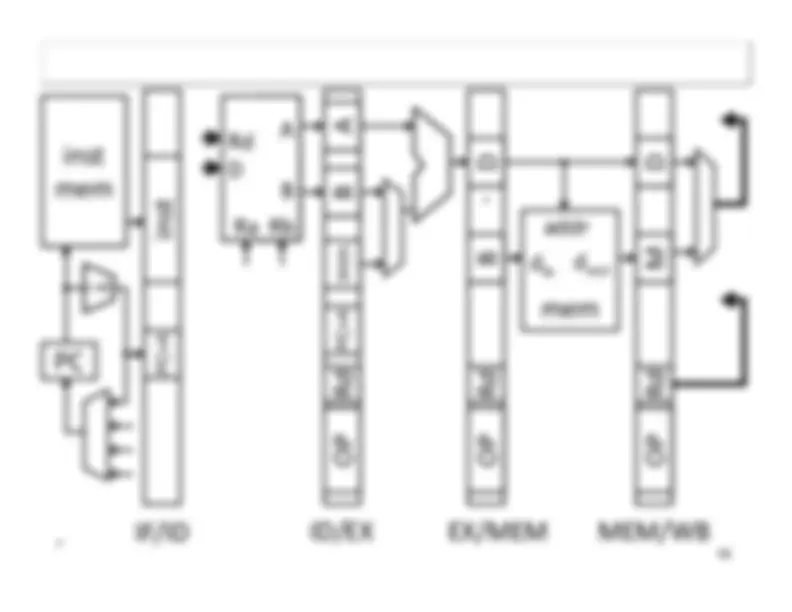
Five stage “RISC” load-store architecture. 1. Instruction fetch (IF). – get instruction from memory, increment PC. 2. Instruction Decode (ID).
Typology: Lecture notes
1 / 59

This page cannot be seen from the preview
Don't miss anything!
Hakim^ WeatherspoonCS^ 3410,
Spring^2012 Computer^ ScienceCornell^ University
See^ P&H^ Chapter
alu
PC
imm memory
addrd d^ in^ out memory
offset^ target
=? cmpcontrol new^ pc
registerfile inst
extend Review:^ Single^ +4^ +
cycle^ processor
Cycle^ per
instruction
make^ logic
and^ clock
simple
instructions
take^ different
time^ to^ finish,^ memory
and^ functional
unit^ are not^ efficiently
utilized.
-^ Cycle^ time
is^ the^ longest
delay.
CPI^ is^1
lower^ MIPS
and^ longer
clock^ period
(lower^ clock
frequency);
hence,^ lower
performance.
MIPS^ and
smaller^
clock^ period
(higher^ clock
frequency) • Hence,^ better
performance
than^ Single
Cycle^ processor
CPI^ than
single^ cycle
processor
-^ want^ small
CPI^ (close
to^ 1)^ with
high^ MIPS
and^ short
clock^ period
(high^ clock
frequency)
-^ CPU^ time
=^ instruction
count^ x^
CPI^ x^ clock
cycle^ time
Saw^
Drill^
Glue^
Paint
Alice Bob Carol Dave
time 1 2
alu
PC
imm memory
addrd d^ in^ out memory
offset^ target
=? cmpcontrol new^ pc
registerfile inst
extend Review:^ Single^ +4^ +
cycle^ processor
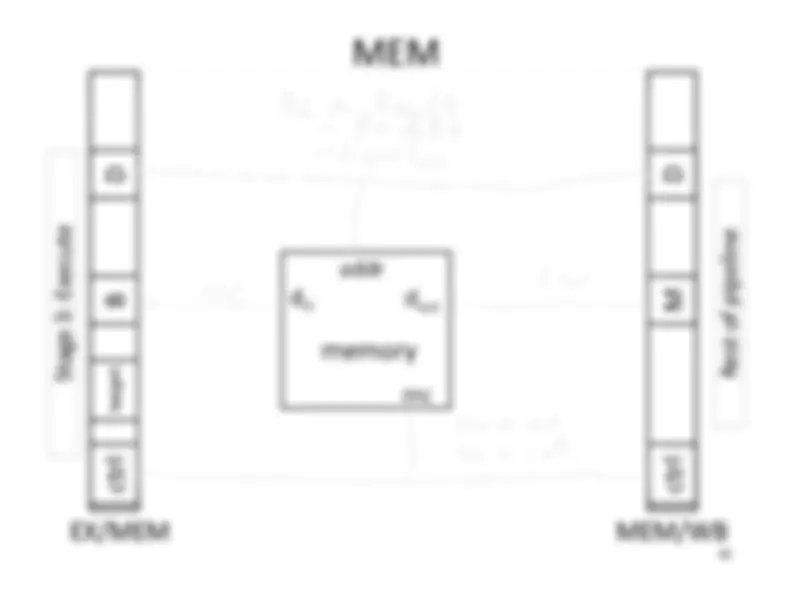
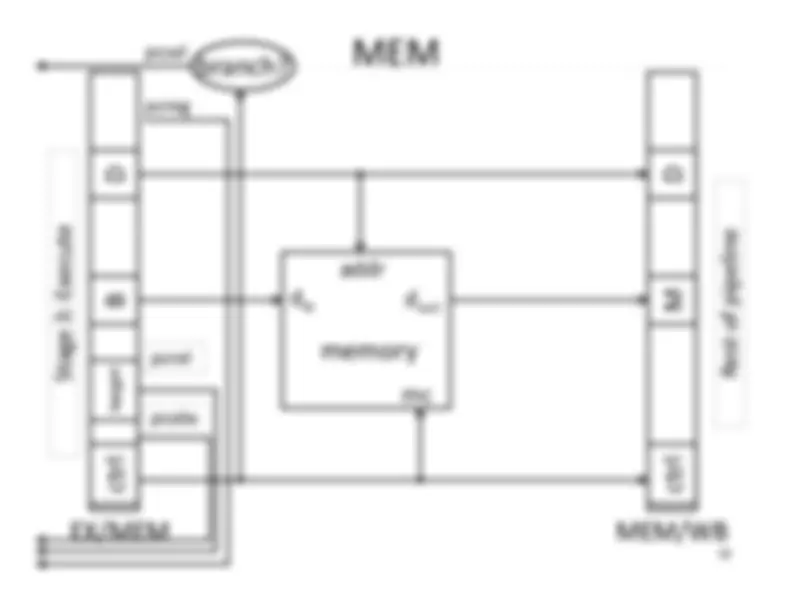
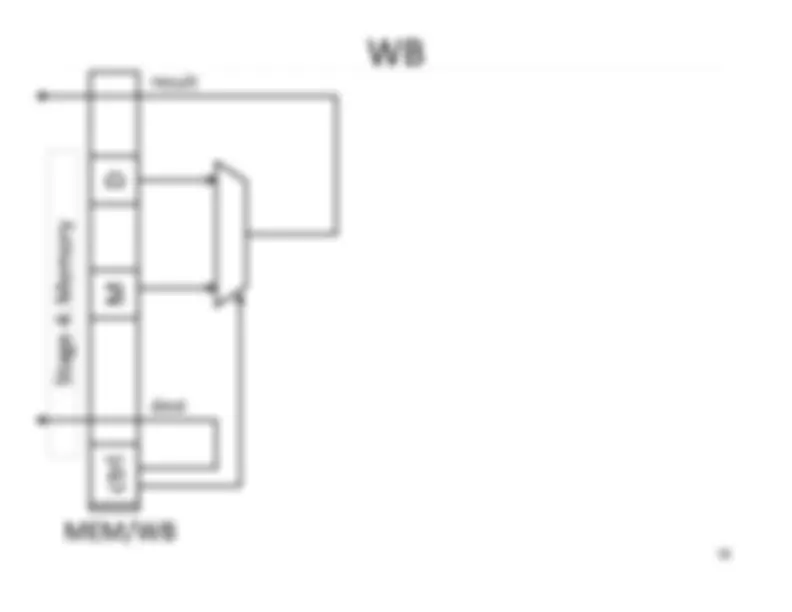
Write‐^ Back^17 Memory
InstructionFetch^
Execute
alu
imm
addrd d^ in^ out memory
inst memory PC
computejump/branchtargets
+4 new pc
extend
1 2
3 4
5 6
7 8
9
Clock^ cycle IF^ ID^ Latency:Throughput:Concurrency: