



CODIGO GENETICO Y GENERALIDADES DE
TRADUCCION













Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Asignatura: Biosíntesis de Macromoléculas, Profesor: Pepe Gavilanes, Carrera: Bioquímica, Universidad: UCM
Tipo: Apuntes
1 / 23

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
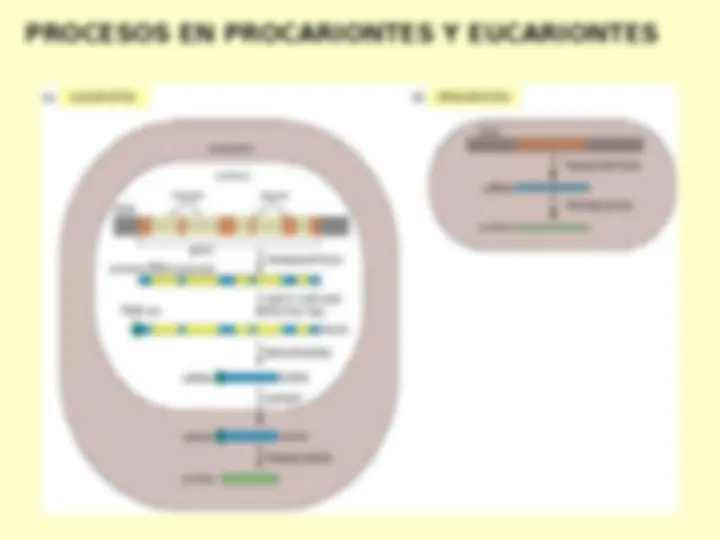
Corresponde al proceso en la
cadena de producción de una
proteína donde tiene lugar la
lectura de una combinación de
bases nitrogenadas
provenientes del RNAm.
Por lo tanto, se define como
mecanismo de traducción a la
determinación de una
secuencia aminoacídica.
Procariontes = proceso “in
toto”.
Eucariontes = proceso
citoplasmático.
3
En 1961, al estudiar las mutaciones inducidas por la proflavina en el
bacteriofago T4, Francis Crick y Sydney Brenner, determinaron el
carácter de tripletes del código genético.
Las conclusiones a las que llegaron son las siguientes:
1.- El código genético es leído de forma secuencial, iniciando en un
punto fijo en el gen. La inserción o supresión de un nucleótido modifica
el marco de lectura en el cual los nucleótidos son leídos como codones
(a estas mutaciones también se les denomina mutaciones de
corrimiento del marco de lectura). Por lo tanto, el código no tiene
puntuaciones internas que indiquen el marco de lectura. Esto significa
que el código genético está libre de comas (o espacios).
2.- El código genético es un código de tripletes.
3.- Todos o casi todos los 64 codones codifican para un aminoácido; lo
que significa que el código es redundante.
Cada tRNA contiene
una secuencia
trinucleotídica
denominada anticodón
que es complementaria
con un codón en el
mRNA para un
aminoácido específico.
Cada aminoácido es
unido a su tRNA
correspondiente a
través de la acción de
una enzima específica
que reconoce ambas
moléculas (el proceso se
denomina "cargado").
Durante muchos años se pensó que el código genético estándar
(mostrado en la Tabla de codones anterior), era universal. Esta
observación se debió a que muchos genes de diferentes organismos
(por ejemplo los de humano), pueden ser traducidos por Escherichia
coli ; este hecho es la base de la Ingeniería Genética.
En 1981 se describió que el código genético de ciertas mitocondrias
(en ellas existe la maquinaria para sintetizar entre 10 y 20 proteínas
mitocondriales, el resto proviene de información en el núcleo), es una
variante de código genético estándar.
Por ejemplo en las mitocondrias de mamíferos, AUA así como AUG
(en el código estándar) es el codón iniciación/Met; UGA especifica Trp
en vez de la señal de terminación. AGA y AGG son señales de
terminación en vez de Arg.
De esta manera las mitocondrias simplifican el código estándar
incrementando la degeneración.
Los ribosomas se observaron por primera vez la década de los
30´s por Albert Claude en homogenizados celulares utilizando
microscopía de campo oscuro.Claude los denominó
"microsomas".
Fue hasta la década de los 50´s cuando George Palade los
observó por microscopía electrónica, pero pensó que eran
artefactos de la técnica.
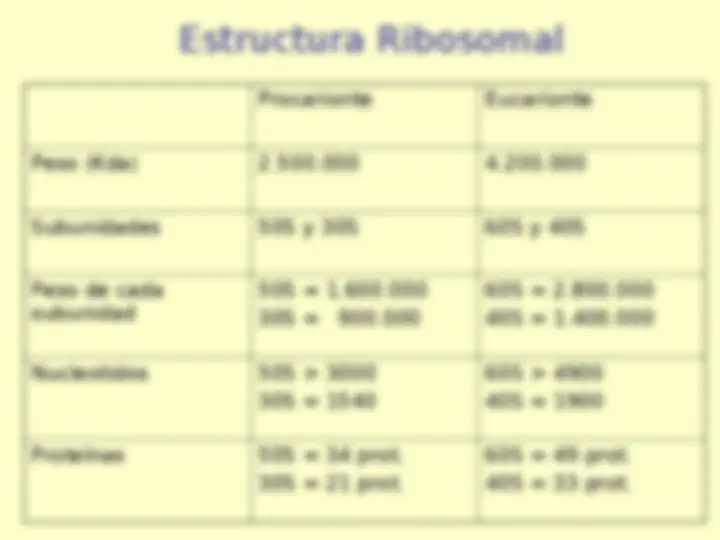
El nombre de ribosomas deriva de que en Escherichia coli ,
están formados por aproximadamente 2/3 partes de RNA y 1/3 de
proteína (los microsomas son en realidad las vesículas formadas
por el retículo endoplásmico, son ricos en ribosomas y es posible
aislarlos por centrifugación diferencial).
Las proteínas ribosomales son difíciles de separar por que ellas
son insolubles en agua. Por convención las proteínas de la
subunidad grande se denominan L y las de la pequeña S (de
L arge y S mall), seguido de un número que indica su posición de
arriba a la izquierda hacia abajo a la derecha en una
electroforesis en gel de doble dimensión