Vista previa parcial del texto
¡Descarga practicqa y más Ejercicios en PDF de Estadística solo en Docsity!
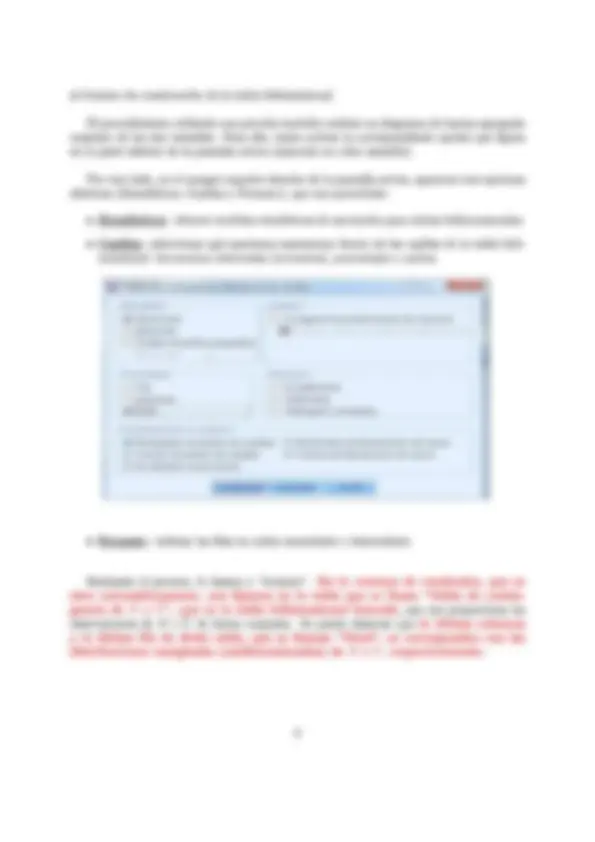
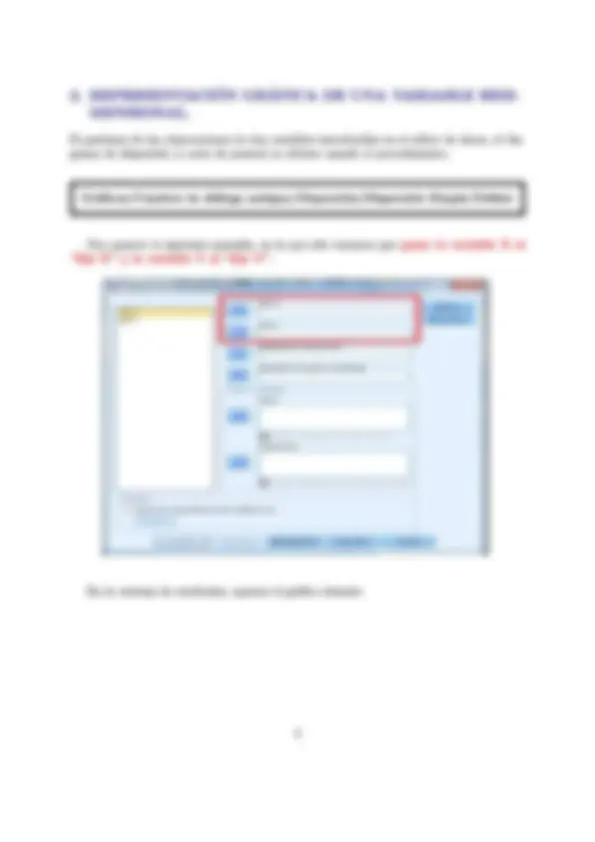
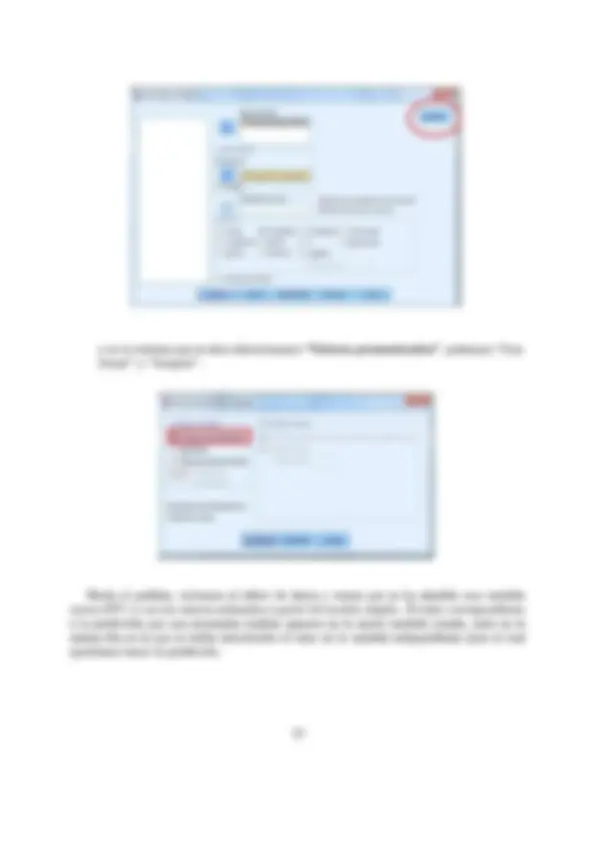
Curso 2017/18 Asignatura: Estadística Estudios: Grado en ADE, FYCO, Economía, Marketing e Investiga- ción de Mercados, Titulación Doble Universidad de Almería DPTO. DE MATEMÁTICAS PRÁCTICA 2: ANÁLISIS DE DATOS BIVARIANTES Objetivos: + Representar númericamente, mediante la tabla bidimensional de frecuencias (correlación o contingencia), una variable bidimensional. + Representar gráficamente, mediante el diagrama de dispersión (nube de puntos), una variable bidimensional. + Obtener distribuciones condicionadas y calcular determinadas medidas estadísticas de interés en dichas distribuciones. e Realizar estudios de Regresión y Correlación, lineal y no lineal, entre dos variables cuantitativas que sean estadísticamente dependientes. e Con el mejor modelo obtenido para expresar la relación entre dos variables dependien- tes, predecir el valor aproximado que tomará una de las variables (variable dependiente) si conocemos previamente el valor que toma la otra variable (variable independiente o explicativa). Para hacer cualquier estudio de una variable bidimensional, lo primero, es definir en el SPSS las dos variables con las que vamos a trabajar. Recordemos, por la práctica anterior, que esto se hacía en el Editor de datos, en la pestaña “vista de variables”. Una vez definidas las dos variables, en la pestaña “vista de datos”, introducimos en dos columnas (una para cada variable), los distintos valores que toma cada una de ellas. Una vez definidas las variables e introducidos sus valores, ya estamos en condiciones de hacer cualquier análisis estadístico bidimensional que nos pidan. 1. REPRESENTACIÓN NUMÉRICA DE UNA VARIABLE BL DIMENSIONAL. Si partimos de las observaciones de dos variables introducidas en el editor de datos, la tabla bidimensional se obtiene usando el menú: stadísticos descriptivos/Tablas de contingencia Automáticamente, se abre la siguiente pantalla dividida en dos partes. [3 Tablas de contingencia 4 [57 1 Filas: Columnas: "Capa 1 de 1 Antenor guiente q | Un) 105 (gesttiaces] (Cancelar. J(_ Aqua.) En el lado izquierdo de la pantalla, aparece el listado de todas las variables que están definidas en el editor de datos. En ese listado, buscamos la variable que nosotros vamos a considerar como la variable X, y la pasamos (o bien arrastrándola con el ratón o bien marcándola y pulsando en la flecha que aparece) donde pone “Filas”. Siguiendo el mismo procedimiento buscamos, en el listado de variables, la variable que nosotros vamos a consid- erar como la variable Y y la pasamos donde pone “Columnas”. De este modo es como se generan las filas y columnas de la tabla bidimensional. Cabe señalar que la información representada en la tabla bidimensional de frecuencias no se ve afectada por la selección de variables para rellenar los campos “filas” y “columnas” (podíamos haber escogido la variable Y para formar las filas de la tabla y la variable X para formar las columnas), ésto sólo afecta 2 2. REPRESENTACIÓN GRÁFICA DE UNA VARIABLE BIDI- MENSIONAL. Si partimos de las observaciones de dos variables introducidas en el editor de datos, el dia- grama de dispersión (o nube de puntos) se obtiene usando el procedimiento: Gráficos/Cuadros de diálogo antiguo/Dispersión/Dispersión Simple/Definir Nos aparece la siguiente pantalla, en la que sólo tenemos que pasar la variable X al “Eje X” y la variable Y al “Eje Y”. Diagrama de dispersión 1232] E ] e fil a 1] E) Establecer marcas por: pS los casos mediante: ] E Ml o Columnas: m | — Plantilla E) Usarlas especificaciones gráficas de: Aceptar A BLEgar [Restablecer] Zest ecer [_Cancetar ) a Lamas) En la ventana de resultados, aparece el gráfico deseado. 3. DISTRIBUCIONES CONDICIONADAS. Para obtenerlas, hay que dar dos pasos: e En primer lugar, hay que indicar la condición, es decir, seleccionar los datos con los que queremos realizar el estudio. Para ello, usamos el menú: Datos/Seleccionar Casos Nos aparece la siguiente pantalla: a SI Lx SY => O Muestra aleatoria de casos Lsetempra O Basándose en el rango del tiempo o de los casos (úrango-) O Usar variable de filtro: 53 1 Resultado (O Descartar casos no seleccionados O Copiar casos seleccionados a un nuevo conjunto de datos O Eliminar casos no seleccionados Estado actual: No filtrar cas: ( en la que debemos marcar la opción: “Si se satisface la condición” y seguidamente, pinchar en el botón que se activa “Si la opción”. siguiente pantalla: A continuación, nos aparece la Archivo Edición Ver Datos Transformar Analizar Marketing dire SECTA ASE 5 -x Y T 1.6 Not Selected 1.6 Not Selected 2.4 Not Selected 2.8 Not Selected 2.9 Not Selected 3.0 Not Selected 3.0 Not Selected x 3,2 Selected 3.5 Selected 3.5 Selected 3.8 Selected 4.0 Not Selected 4.4 Not Selected 4,5 Not Selected e En segundo lugar, una vez indicada la condición, tenemos que obtener la dis- tribución unidimensional de la variable de interés. Recordemos, por la práctica anterior, que esto se obtiene mediante el menú: Analizar /Estadísticos descriptivos /Frecuencias Pasamos la variable de estudio y marcamos donde pone “Mostrar tabla de frecuencias”. Si, además, queremos hacer algún análisis estadístico en la distribución condicionada, lo seleccionamos en la opción “Estadísticos”. En la ventana de resultados que se abre automáticamente, aparece una tabla de frecuencias, que es la distribución condicionada buscada. Por último, para que el ordenador vuelva a trabajar con todos los datos recogidos, tene- mos que volver a pinchar en: Datos/Seleccionar Casos y marcar la opción: “Todos los casos”. 4. REGRESIÓN Y CORRELACIÓN ENTRE DOS VARIABLES ESTADÍSTICAS. Usaremos el procedimiento: con el que obtenemos el valor de los coeficientes y los gráficos de distintos modelos de regresión lineal y no lineal. han de ser numéricas. Ambas variables, tanto la dependiente como la independiente AAA == porencores: a... 5 [E3] SY nn O Variante O tiempo Etiquetas de caso: [5 Incluir ta constante en la ecuación e praia das muaa Dr Y Lineal IZ Cuadrático [| Compuesto [U] Crecimiento 7 Logurtrico El Cáetco ES [E Economias | inverso. ¡MfPoiensia] [El Logística y Vertabia ds ANOVA Escogemos una variable numérica como dependiente (la que queremos predecir) y otra como independiente (o explicativa, en función de la cual queremos explicar la variable dependiente). Seleccionamos el modelo o modelos que queremos ajustar a las dos variables. De entre todos los ofertados por el programa, nosotros nos limitaremos a trabajar con los siguientes: lineal, parábola (cuadrático), hipérbola (inverso), potencial (potencia) o exponencial (compuesto). Incluimos constante en la ecuación. Si seleccionamos Representar los modelos, representaremos gráficamente las funciones de regresión seleccionadas. En la pantalla de resultados, nos tenemos que fijar en la tabla “RESUMEN DEL MODELO Y ESTIMACIONES DE LOS PARÁMETROS”. En concreto, nos fijamos en el valor de “R cuadrado”, que es el coeficiente de determinación obtenido con cada modelo, y en “Estimaciones de los parámetros”, que nos proporciona el valor 8 peso perdido, en KG T T 7 7 75 100 125 150 tiempo, en semanas, siguiendo la dieta Así, observamos que en la sección “Línea de referencia”, me proporciona la ecuación completa del modelo e incluso permite adjuntarla al gráfico de dispersión. Fijaren: | Eje de categorías Variable: Posición Ecuación personalizada y= [0,5107621824710131 + 0,4155920056808428 =x + -0,0114443340 (4185455 “xx Operadores válidos: +.-,*/,(), y ** Tajuntar stqueta a lnea 1 Obteniéndose como resultado que, en el diagrama de dispersión, el modelo figura su correspondiente ecuación. 10 peso perdido, en KG O Observado —inea Inverso Cuadrático —- compuesto. - - Potencia TIOS 041 SO 1AdA3A0810SASS * xx 25 so 75 100 125 150 2ODS5S0S4za + tiempo, en semanas, siguiendo la dieta | Predicciones Recordemos que el objetivo último de la Regresión es el de realizar predicciones sobre el valor de la variable dependiente, para un valor concreto de la variable independiente. Una vez que hemos obtenido la expresión del mejor modelo, esta predicción se puede realizar sin más que sustituir el valor concreto de la variable independiente en la expresión obtenida. Por ejemplo, supongamos que queremos predecir el peso que se perdería con la dieta si se sigue dicha dieta por un periodo de 9 semanas. Entoces, nos basta con realizar el siguiente cálculo: pesoperdido = 0.611 + (0.416) - (9) — 0.011 - (9)? = 3.464 con lo que se perderían aproximadamente 3.464 kilogramos. Otra opción alternativa para realizar la predicción de valores es utilizar el SPSS. El procedimiento es el siguiente: 1. En la pestaña “Vista de datos” del Editor de datos, se añade en la columna co- rrespondiente a la variable independiente el valor concreto para el cual queremos realizar la predicción, mientras que la casilla correspondiente a la variable dependiente se deja vacía. 11 ca Dependientes: f Independiente: [ (O) Variable: [v/ Representar los modelos pues E) Lineal [Y Cuadrático ["] Compuesto [7] Crecimiento E Logarítmico [E] Cúbico [6 1D Exponencial E inverso — [El Potencia: (El Logística Límite superior. El Vertabla de ANOVA ——, Etiquetas de caso; [4 Incluirla constante enla ecuación y en la ventana que se abre seleccionamos “Valores pronosticados”, pulsamos “Con- tinuar” y “Aceptar”. 4 ESTE E 7] (E) Estimación curvilínea: Guardar =>) Pronosticar casos: [Y Valores pronosticados eríodo de estimación hasta el último caso [O Residuos [Intervalos de pronóstico El período de estimación es: Todos los casos Hecho el análisis, volvemos al editor de datos y vemos que se ha añadido una variable nueva (FIT_1) con los valores estimados a partir del modelo elegido. El valor correspondiente a la predicción que nos interesaba realizar aparece en la nueva variable creada, justo en la misma fila en la que se había introducido el valor de la variable independiente para el cual queríamos hacer la predicción. 13 Archivo Edición Ver Datos Transformar Analizar Marketing directo Gráficos Uñilidac SM ->- Aron ssl En el caso de nuestro ejemplo, vemos que se ha obtenido un valor de 3.42410 Kgr (un valor muy próximo al obtenido cuando hicimos la operación del pronóstico a mano). OBSERVACIÓN IMPORTANTE: recordemos que sólo debemos realizar predicciones de la variable dependiente, usando el mejor modelo ajustado, para valores de la variable independiente que se encuentren dentro del rango de valores observados de dicha variable. 14 9 3.42410] x [[ Y [ FM_1 [var [var | yv 4 1,6 2.09002 5 24 2,40261 6 28 2.69232 5 29 2,40261 6 3,0 2.69232 8 3,0 3,20306 8 3,2 3,20306 8 3.5 3.20306 mM 3,5 3,79751 13 3.8 4,07937 13 4.0 4.07937 15 44 4,26967 16 45 4. 33048 Ejercicio 2 Una empresa de manufacturas basa las predicciones de sus ventas anuales en los resultados oficiales de la demanda total en la industria. A continuación, se dan los datos de demanda total y las ventas efectuadas por la empresa en los últimos 11 años. Demanda Total (miles de tm) | Ventas (miles de tm) 200 9 220 6 300 12 330 7 210 E 390 10 280 8 140 y 280 7 290 10 380 17 Se pide: 1. Agrupar la variable Demanda Total en tres intervalos de amplitud 90 y la variable Ventas en dos intervalos de amplitud 5. Obtener la tabla bidiemensional de fre- cuencias, mostrando tanto el recuento como el porcentaje, de las variables Demanda Total y Ventas agrupadas en intervalos. Con la información obtenida, contesta las siguientes cuestiones: e ¿En qué porcentaje de años la Demanda Total ha sido inferior a 230000 tm? e ¿En cuántos años la Demanda Total ha sido superior o igual a 230000 e inferior a 320000 tm y las Ventas han sido inferiores a 9000 tm? e ¿En qué porcentaje de años las Ventas son igual o superior las 9000 tm? e ¿Se observa dependencia estadística entre la Demanda Total y las Ventas en los datos muestrales? 2. Calcular el volumen de Ventas más habitual en la empresa si la Demanda Total es superior o igual a 280000 tm. 3. Para los años en los que las Ventas han sido inferiores a 9000 tm, obtener la Demanda Total media. 4. Mediante un diagrama de dispersión, comprobar si tendría sentido o no ajustar un mo- delo lineal entre las variables Demanda Total y Ventas. En caso afirmativo, índica el signo que tendría el coeficiente de regresión (pendiente de la recta) e interprétalo. 16 5. Encontrar el modelo de regresión más fiable que nos permita predecir las Ventas de la empresa en función de la Demanda Total. Si la Demanda Total industrial es de 300000 toneladas, ¿Qué volumen de ventas se puede predecir que tendría la empresa? ¿Qué fiabilidad tiene la predicción que acabamos de realizar? Ejercicio 3 Para realizar un estudio sobre la utilización de una impresora en un determi- nado departamento, se midió en un día los minutos transcurridos entre las sucesivas utiliza- ciones (X) y el número de páginas impresas (Y) obteniéndose los siguientes resultados: X:9,9,4,6,8,9,7,6,9,9,9, 8,8, 9, 8,9, 9, 9, 10, 9, 15, 10, 12, 12, 10, 10, 12, 10, 10, 12, 12, 10. Y:3,8,3,8,3,8,8,8,3,8,12, 12, 8, 8, 8, 12, 12, 20, 8, 20, 8, 8, 20, 8, 8, 12, 8, 20, 20, 3, 3, 20. Se pide: 1. Mostrar la tabla bidiemensional de frecuencias, representando tanto el recuento como el porcentaje. Con la información obtenida, contesta las siguientes cuestiones: e ¿Cuantas veces se imprimen como mucho 8 páginas? e ¿Cuántas veces se imprimen menos de 12 páginas y transcurren 9 minutos desde la anterior utilización? e ¿Cuál es el porcentaje de veces que transcurre más de nueve minutos desde la anterior utilización y se imprimen menos de 12 páginas? 2. De entre los casos en los que han transcurrido más de 9 minutos entre utilizaciones sucesivas, calcula el número máximo de páginas que se imprimen en el 20% de los casos en los que menos páginas se imprimen. 3. Si transcurren 7 o más minutos y menos de 12 minutos entre utilizaciones sucesivas, obtener el número de páginas impresas más habitual. 4. Encontrar el mejor modelo de regresión que nos permita predecir las páginas que se imprimen Y, a partir del tiempo que transcurre entre utilizaciones sucesivas X. Con dicho modelo, estima el número de páginas que se imprimirían si han transcurrido 11 minutos entre utilizaciones sucesivas ¿En qué medida confiarías en la estimación que acabas de realizar? 17 5. Dar la expresión del mejor modelo matemático que nos permita predecir el peso perdido en función del tiempo, en semanas, que se lleva de dieta. Utilizando dicho modelo, ¿cuánto peso perderá una persona que lleve 9 semanas de dieta? ¿Qué fiabilidad tiene la predicción que acabas de realizar? ¿Sería posible estimar el peso perdido para una persona que lleve 18 semanas de dieta? Ejercicio 5 Se ha preguntado 16 alumnos que cursan su primer año de estudios en la Uni- versidad, por las siguientes cuestiones: e Ideología política:(I: Izquierda/ D: derecha / C: centro). + Opinión sobre el aborto: (0: En ningún caso/ 1: por necesidad/ 2: decisión libre). e Edad. Los resultados obtenidos, han sido los siguientes: Ideología| I|D|C|I[D|D|I1|C|D|I|C|D|D|D|C|D Opinión [| 0 | 2 | 1|2|0|1|1|0|2|1|2|1|1|0|1]|1 Edad 19|20| 22|34|19| 21|20| 22| 19| 20 | 21| 25| 21| 22| 19| 19 Estudiar si para la muestra tomada se aprecia o no dependencia estadística entre la “Ideología política” y la “opinión sobre el aborto” ¿Y entre las variables “opinión sobre el aborto” y “Edad”? 19