



APRENDIZAJE AUTO M ´
ATICO
Daniel Borrajo
UC3M

















Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
El concepto de procesos de decisión markov (mdp) en aprendizaje automático. Se trata de un modelo matemático para tomar decisiones en entornos estocásticos, donde el agente debe aprender una estrategia reactiva (política) que maximice el valor esperado de la recompensa. Se presentan tipos de mdp, un ejemplo de robótica y un ejemplo de control de semáforos, así como dos alternativas para resolverlos. Además, se menciona el aprendizaje q-learning.
Tipo: Diapositivas
1 / 42

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Daniel Borrajo
UC3M
1 Introducci ´on
2 Generaci ´on de ´arboles y reglas
3 Regresi ´on
4 Otras t ´ecnicas
5 Aprendizaje basado en instancias y no supervisado
6 Conjuntos de clasificadores y Reglas de asociaci ´on
7 Aprendizaje por refuerzo
8 Programaci ´on L ´ogica Inductiva
9 Aprendizaje en resoluci ´on de problemas
1 Introducci ´on 2 Generaci ´on de ´arboles y reglas 3 Regresi ´on 4 Otras t ´ecnicas 5 Aprendizaje basado en instancias y no supervisado 6 Conjuntos de clasificadores y Reglas de asociaci ´on 7 Aprendizaje por refuerzo 8 Programaci ´on L ´ogica Inductiva 9 Aprendizaje en resoluci ´on de problemas
1 Introducci ´on 2 Generaci ´on de ´arboles y reglas 3 Regresi ´on 4 Otras t ´ecnicas 5 Aprendizaje basado en instancias y no supervisado 6 Conjuntos de clasificadores y Reglas de asociaci ´on 7 Aprendizaje por refuerzo 8 Programaci ´on L ´ogica Inductiva 9 Aprendizaje en resoluci ´on de problemas
1 Introducci ´on 2 Generaci ´on de ´arboles y reglas 3 Regresi ´on 4 Otras t ´ecnicas 5 Aprendizaje basado en instancias y no supervisado 6 Conjuntos de clasificadores y Reglas de asociaci ´on 7 Aprendizaje por refuerzo 8 Programaci ´on L ´ogica Inductiva 9 Aprendizaje en resoluci ´on de problemas
1 Introducci ´on 2 Generaci ´on de ´arboles y reglas 3 Regresi ´on 4 Otras t ´ecnicas 5 Aprendizaje basado en instancias y no supervisado 6 Conjuntos de clasificadores y Reglas de asociaci ´on 7 Aprendizaje por refuerzo 8 Programaci ´on L ´ogica Inductiva 9 Aprendizaje en resoluci ´on de problemas
4.5 3.70.1sí −2... g girar 3.7 3.50.1 sí ... g
−
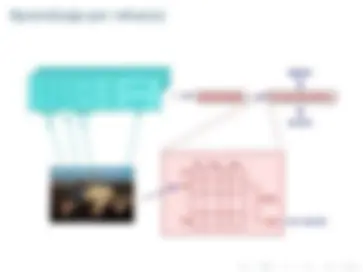
103.45 Aprendizaje^ Comportamiento
estado
acción
acción
a 1 a 2 a (^) n e (^1) e (^2)
m
.
e
..
...
max
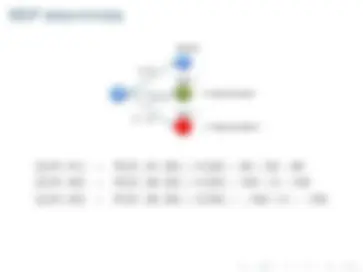
s 0 a 0 r 0 −→ s 1 a 1 r 1 −→ s 2 a 2 r 2 −→...
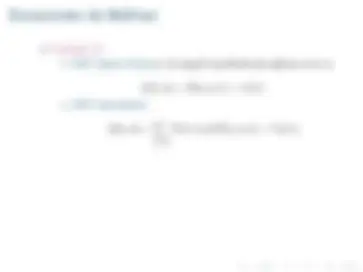
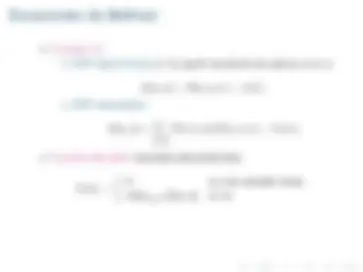
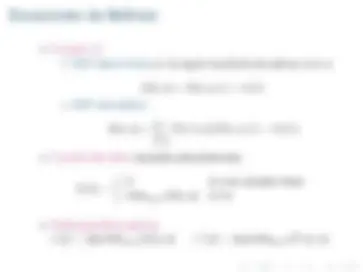
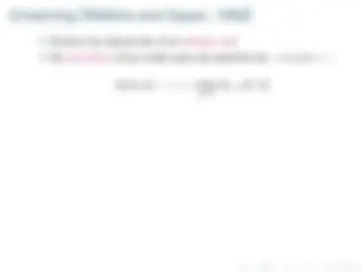
r 0 + γr 1 + γ^2 r 2 +... 0 ≤ γ ≤ 1 donde γ es el factor de descuento
V π^ (et ) =
∑^ h
i= 0
γi^ R(et+i , at+i , et+i+ 1 )
V π^ (et ) =
∑^ h
i= 0
γi^ R(et+i , at+i , et+i+ 1 )
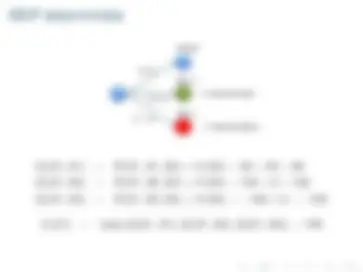
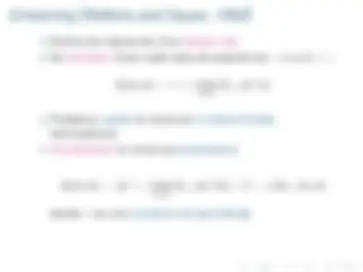
Dos alternativas
V (S 1 ) = m ´ax{Q(S 1 , A 1 ), Q(S 1 , A 2 ), Q(S 1 , A 3 )} = 100
π(S 1 ) = arg m ´ax Ai
Q(S 1 , Ai) = A 2