Scarica Documento utile allo studio e più Guide, Progetti e Ricerche in PDF di Storia della lingua italiana solo su Docsity!
VALENTINA DE IACOVO 1 - MARCO PALENA 2
La variazione prosodica in italiano: l’utilizzo di un chatbot
Telegram per la didattica assistita per apprendenti
di italiano L2 e nella valutazione linguistica
delle conoscenze disciplinari
Abstract
The comparison of foreign language learners’ pronunciation with the utterances of native speakers is receiving increasing attention thanks to the new applications of computer-assist- ed teaching. The studies on prosodic variation between several native speakers reveal rhyth- mic-intonative patterns that should be part of the linguistic baggage of the native speaker; it seems problematic how to make explicit to the learner his degree of prosodic competence on the basis of the different acoustic indices (f0, intensity, pitch) and other parameters (number of syllables, lexical accent, speech rate, pauses). We present a chatbot designed as a proactive learning support for the improvement of oral skills in Italian L2. After describing its tech- nical structure, the first results of a preliminary study are discussed. They provide a first starting point to reflect on some considerations that emerged.
1. Introduzione
Le caratteristiche prosodiche del parlato rivelano importanti informazioni come la modalità enunciativa, lo stile d’eloquio, l’attitudine e le connotazioni diatopiche o diastratiche del locutore; esse sono quindi essenziali per una buona riuscita del- la comunicazione interlocutiva (Hirst 1983, Cruttenden 1986). Tuttavia, in molti contesti relativi alla didattica delle lingue straniere (LS) la riflessione metaprosodica non è sempre soddisfacente per lo studente poiché non viene affrontata in modo esaustivo (Trouvain & Gut 2007). Riferirsi al ruolo di caratteristiche prosodiche come l’intonazione, il ritmo, la durata, la focalizzazione per spiegare differenze comunicative di significato può invece rivelarsi indispensabile per innescare nello studente una consapevolezza utile per riconoscere e riprodurre il parlato della LS (Cresti 1999, Chun 2002, Frost & Picavet 2014). Inoltre, ormai da diversi decenni, gli sviluppi tecnologici nell’analisi del parlato hanno aperto la strada a nuove pro- spettive di interazione comunicativa declinabili anche per la didattica delle lingue (Chun 1998, Cazade 1999), facendo emergere, sin dai primissimi studi condotti, anche varie criticità verso le possibili soluzioni di esplicitazione del grado di compe-
(^1) Università degli Studi di Torino. (^2) Politecnico di Torino.
86 VALENTINA DE IACOVO - MARCO PALENA
tenza raggiunto, ad esempio tramite l’utilizzo di rappresentazioni grafiche di sup- porto ( James 1976, De Bot 1983, Martin 2010). La didattica incentrata sull’oralità di una LS permette proprio quel tipo di ri- flessione metaprosodica grazie alla quale lo studente può sperimentare la varietà di combinazioni enunciative presenti nella lingua appresa e associarne il significato in termini di funzioni specifiche (modali, sintattiche, informative, emozionali) per af- finare le proprie competenze comunicative orali (Delattre 1966, Cresti 1999). In italiano bisogna inoltre tener conto delle diverse scelte intonative anche sulla base della varietà diatopica utilizzata (Canepari 1985, Sorianello 2006), una fonte di va- riabilità inclusa ormai da diverso tempo negli spazi della ricerca sull’intonazione della L2 (De Meo & Pettorino 2012, De Marco et al. 2014) che, discussa nei conte- sti didattici, porterebbe a una maggior sensibilizzazione da parte dell’apprendente, molto spesso esposto a un solo modello diatopico. Infine, ci sembra interessante sof- fermarci sulle diverse possibilità di realizzazione tipiche della lingua orale e su come occorra tenerne conto nel contesto della valutazione automatica e nella ricorrenza di andamenti intonativi. Sulla base di queste considerazioni, questo studio si struttura nel seguente modo: dopo aver presentato l’architettura del chatbot, analizzeremo come avviene il confronto tra i dati di parlanti madrelingua italiana e apprendenti di italiano L a partire da un set di dieci frasi complesse costruite in modo da dare un’adegua- ta rappresentazione delle più frequenti soluzioni intonative di un parlato elicitato su contenuti di natura tecnico-scientifica, includendo però al tempo stesso anche alcune espressioni quotidiane. Discuteremo infine, sulla base dei risultati ottenuti da parte degli italofoni e degli studenti, una serie di riflessioni nell’ottica futura di implementare successivi parametri per la valutazione del chatbott, nello specifico in che modo i valori dei parametri acustici rilevati dal chatbot rispecchiano una valuta- zione percettiva (Munro & Derwing 1999).
2. Architettura e funzionamento del chatbot
In questo paragrafo illustriamo in che modo è stato strutturato il chatbot tt^3 come stru- mento di didattica assistita per la valutazione di tratti prosodici. L’adozione di un chatbot di questo tipo permette diversi vantaggi. Innanzitutto prevede una modalità di interazione, basata su testo, a cui il pubblico è già largamente abituato grazie alla popolarità di applicazioni di messaggistica instantanea quali Whatsapp o Telegram. Ciò rende questi strumenti più facilmente fruibili rispetto ad applicazioni dedicate o ai cosiddetti Learning Management System (LMS) come Moodlee oBlackboarddd, il cui maggior ostacolo alla fruibilità è rappresentato proprio dalla necessità da parte degli utenti di adattarsi a un’interfaccia poco familiare. Un chatbott permette inol- tre di interagire con gli apprendenti in maniera strutturata e asincrona: strutturata
(^3) Il chatbott è un software progettato per simulare una conversazione con un utente umano (Fernoagăet alll. 2018) che vede, tra le diverse applicazioni, anche quella educativa e didattica (Colace et al. 2018).
88 VALENTINA DE IACOVO - MARCO PALENA
lori di frequenza fondamentale (fff ) dei foni vocalici 0 6 precedentemente identificati, ottenendo così la curva intonativa dell’enunciato (per il modello di segmentazione ed estrazione dei valori, cfr. Romano et alll. 2014).
Figura 1 - Finestra di Praat (wav e Textgrid) con la segmentazione fonetica effettuata da WebMaus della frase “Non avere nessuna possibilità di agire come si vorrebbe”
L’analisi dell’intonazione avviene mediante il confronto tra la curva intonativa dell’enunciato dell’apprendente e i tracciati fff dei corrispettivi enunciati di parlanti 0 madrelingua, precedentemente raccolti e valutati utilizzando la medesima procedu- ra automatica. Il confronto avviene mediante il calcolo di una misura di correlazio- ne (Castro Moutinho et alll. 2011) che confronta per ogni frase tre punti (iniziale, centrale, finale) di f ff 0 di ogni segmento vocalico individuato da Maus. Data la natura estemporanea dei segnali vocali registrati e la modalità automatica della procedura di segmentazione operata da Maus, i segmenti vocalici rilevati per gli enunciati de- gli apprendenti e quelli rilevati per i corrispettivi enunciati di parlanti madrelingua potrebbero differire. Pertanto, prima di calcolare la correlazione, i segmenti dei due parlanti vengono allineati sulla base sia dell’informazione fonetica in essi contenuta sia della loro posizione temporale (fig. 2). Questa procedura di allineamento serve per mettere in corrispondenza i segmenti dei due parlanti in modo da sapere quali confrontare tra loro per il calcolo della correlazione, quindi solo i segmenti per cui si è trovata corrispondenza sono inclusi nel calcolo della correlazione. Sono esclusi invece tutti i segmenti vocalici per cui non si trova corrispondenza fonetica tra i due enunciati. Ad esempio, se l’enunciato di un parlante include in una certa posi- zione un segmento etichettato come [a] mentre l’enunciato dell’altro parlante non lo include, quel segmento non viene preso in considerazione come punto ai fini del calcolo della correlazione. Questo perché per calcolare la correlazione abbiamo bisogno di due serie di dati della stessa numerosità.
(^6) Sono stati considerati solo i segmenti vocalici che MAUS etichetta con i seguenti fonemi: aɶæεœe̞ ø̞ eøiyɪʏɜɞɝɐäɒəɚɨʉɘɵɪ̈ʊ̈ɑɒʌɔɤ̞o̞ɯuʊɤo.
LA VARIAZIONE PROSODICA IN ITALIANO 89
Figura 2 - Audio segmentato, allineamento temporale, corrispondenza dei segmenti
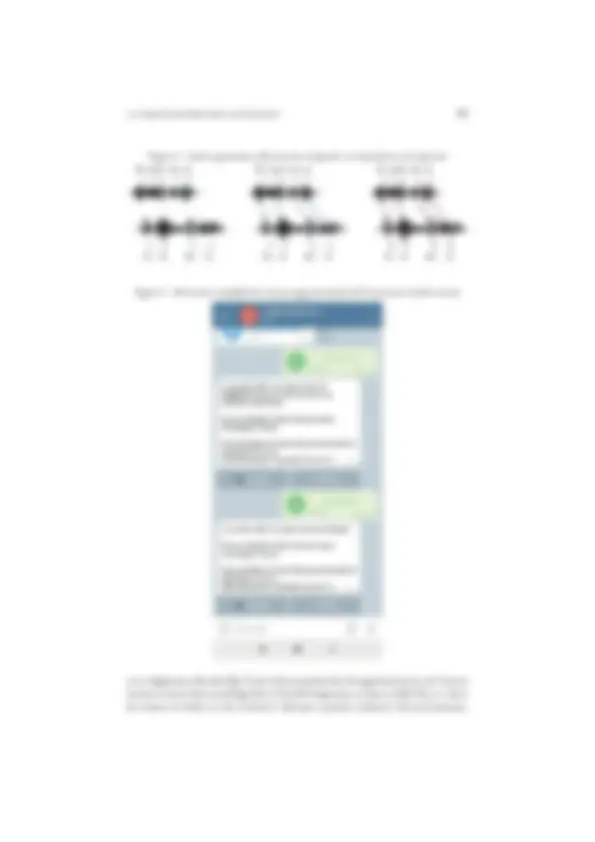
Figura 3 - Schermate esemplificative dei passaggi principali dell’interazione chatbot-utente
Lo svolgimento del task (fig. 3) prevede una prima fase di registrazione in cui l’utente fornisce alcuni dati sociolinguistici (il livello linguistico in base al QCER, se e dove ha vissuto in Italia, in che contesti è abituato a parlare italiano). Successivamente,
LA VARIAZIONE PROSODICA IN ITALIANO 91
pronunciata dallo studente e di restituirne la percentuale di correlazione massima. È importante sottolineare che la percentuale restituita alla fine di ogni risposta data esprime esclusivamente il parametro acustico responsabile dell’intonazione, ovve- ro la frequenza fondamentale (fff ): di conseguenza, per offrire una valutazione più 0 accurata, le frasi di riferimento prodotte dagli italofoni sono state valutate da parte di due operatori umani per poter successivamente correlare alcuni indici acustici (come la velocità d’eloquio, la fluenza o la scansione pausale) con la valutazione percettiva. Nello specifico, per ogni frase si segnalano^12 :
- la velocità di lettura (lenta, normale o veloce);
- l’accento regionale (punteggio da 1 – accento non riconducibile a una speci- fica varietà regionale – a 3 –accento marcato regionalmente);
- la scansione delle parole (lenta, normale o veloce);
- la fluenza intonativa (punteggio da 1 – min spontaneità – a 3 – max sponta- neità);
- l’età del locutore (bambino, ragazzo, adulto o anziano).
4. Primi risultati su un campione di studenti francofoni
In un primo tempo 13 , per testare il chatbot su un gruppo linguistico omogeneo, il task è stato sottoposto a 15 studenti universitari francofoni (12 femmine e 3 ma- schi) di un’età compresa tra i 20 e i 22 anni che studiano l’italiano da 2-5 anni^14 ; dal totale di 150 frasi sono state escluse 15 frasi perché non sono state registrate dall’utente o perché non sono state lette correttamente^15. Le frasi prodotte sono state quindi confrontate con quelle della base di dati che, per questo set, hanno ri- cevuto generalmente una valutazione percettiva massima (97% dei casi) e media (3%). Gli utenti francofoni invece hanno ricevuto un punteggio alto (3) nel 47% dei casi (63 frasi), medio (2) per il 47% (63 frasi) e basso (1) nel restante 6% (9 frasi). Mediamente per ciascuna frase gli utenti hanno ricevuto una valutazione percettiva dell’intonazione di 2 nella metà dei casi e 3 nel restante, tranne la frase 9 per la quale soltanto 5 utenti hanno ricevuto una valutazione media (2). Se osserviamo i con- fronti tra le frasi degli utenti francofoni con i riferimenti italofoni con un punteggio alto, notiamo che la media della vicinanza intonativa delle frasi si attesta tra il 37% e il 94%. Più precisamente 6 frasi hanno una vicinanza compresa tra il 25 e il 50%, 32 tra il 50 e il 75% e 24 tra il 75 e il 100%. Nel confronto grafico di due curve intona-
(^12) In questa sede viene presa in esame soltanto la fluenza intonativa, gli altri parametri percettivi sono in corso di analisi e saranno oggetto di un altro lavoro. (^13) Il task è stato somministrato nel tempo a più gruppi di studenti con provenienza mista (anglofoni, ispanofoni, ecc.) ma per questa prima presentazione si è scelto di focalizzare l’analisi sul campione di francofoni. (^14) In questo lavoro non abbiamo preso in considerazione e correlato le caratteristiche sociolinguistiche degli studenti limitandoci a una presentazione dei dati qualitativa. (^15) In questo caso, ci riferiamo all’ultima frase (“ 1 /6 + 3/2”) che è stata letta “un sesto più tre mezzi” soltanto da 4 utenti.
92 VALENTINA DE IACOVO - MARCO PALENA
tive utente-campione riferimento (fig. 4) con un’alta percentuale di correlazione del 92%, si nota ad esempio un andamento di fff complessivamente simile. 0
Figura 4 - Confronto delle curve intonative tra parlante di riferimento (segmenti continui) e utente (segmenti tratteggiati) della frase “Il 14 luglio 1789” a partire dai valori dei segmenti vocalici estratti (righe verticali)
Figura 5 - Confronto delle curve intonative tra parlante di riferimento (segmenti continui) e utente (segmenti tratteggiati) della frase “Se fossi venuto con me, ti avrei portato a mangiare una pizza” a partire dai valori dei segmenti vocalici estratti (righe verticali)
Sono stati anche analizzati quei casi in cui sia il locoture italofono che l’utente fran- cofono hanno un punteggio percettivo alto (3) ma la percentuale di correlazione intonativa è bassa: poiché ci aspettiamo che laddove la valutazione percettiva sia in entrambi i casi alta, anche il punteggio sia alto, occorre capire se un’eventuale percentuale bassa sia dovuta ad altri fattori (segmentazione di Maus non corretta, qualità scarsa della registrazione, bassa presenza di segmenti allineabili). La figu- ra 5 mostra ad esempio che, nonostante la valutazione percettiva dell’intonazione
94 VALENTINA DE IACOVO - MARCO PALENA
un largo campione, è in corso la fase di quantificazione e soluzione dei casi in cui gli enunciati si presentino difformi da quelli attesi a causa di un ordine di parole diverso e/o della presenza di frammenti involontari di parlato (balbettii, esitazio- ni, false partenze) che causano differenze tali da impedire il conseguimento di una minima distanza prosodica. Dopo aver concluso l’etichettatura della base dati per gli altri parametri descritti, vorremmo concentrarci su quelli prodotti dagli studenti per una valutazione fonetico-percettiva da comparare in un secondo tempo con gli indici acustici principali. In un’ultima fase, vorremmo incrementare ed equilibra- re il corpus di riferimento dei parlanti madrelingua italiani per ampliare le varietà enunciative in termini diatopici e diafasici (Crocco 2017). In questa direzione, un ulteriore passo riguarda l’eventuale classificazione dalla quale partire per addestrare un algoritmo in grado di sostituire l’operatore umano lungo una linea che distingua un parlato più artefatto da uno sciolto e spontaneo (Nencioni 1976, Voghera 1989, Zmarich et alll. 1996). Infine, un aspetto ancora poco approfondito riguarda la lettura di enunciati di lettura più complessa, che prevedano la presenza di semplici formule matematiche, sigle, acronimi e forestierismi, senza trascurare le espressioni richieste dalle soluzioni enunciative tipiche di alcuni linguaggi specialistici. Su questi aspetti nessuna forma- zione specifica è prevista nei curricula di avvicinamento alle materie tecnico-scien- tifiche e nessuna pubblicazione nazionale dà indicazioni esaustive. Ad esempio, per quanto tutti riconoscano espressioni grafiche come “3/2”, “12,1%”, “011 6709718”, “FBI”, “report” etc., non esiste una fonte pubblicamente disponibile in grado di cha- rire a un apprendente di italiano la pronuncia (o le pronunce) più tipiche di questi oggetti linguistici, nelle preferenze dei parlanti nativi (Fry 1989).
Ringraziamenti
Questo progetto ha beneficiato di un finanziamento della Fondazione CRT – Bando Erogazioni Ordinarie 2020 - CALL-UniTO. Si ringrazia la prof.ssa Donatella Bisconti e tutti coloro che hanno preso parte alla registrazione delle frasi e gli stu- denti che si sono sottoposti al task.
Bibliografia
Bailey, D. (2019). Chatbots as conversational agents in the context of language learning. In Proceedings of the Fourth Industrial Revolution and Education, 32-41.
Berruto, Gaetano. 2012. Sociolinguistica dell’Italiano contemporaneo. Roma: Carocci.
Boersma, Paul & Weenink, David. 2018. Praat: doing phonetics by computerr [Computer program]. Version 6.0.37, retrieved 14 March 2018 from http://www.praat.org/.
Busà, Maria Grazia. 2012. The role of prosody in pronunciation teaching: a growing appreciation. In Busà, Maria Grazia & Stella Antonio (eds.), Methodological Perspectives on Second Language Prosody, 101-105. Padova: Cleup.
LA VARIAZIONE PROSODICA IN ITALIANO 95
Canepari, Luciano. 1983. Italiano standard e pronuncia regionale. Padova: CLEUP.
Canepari, Luciano. 1985. L’intonazione. Linguistica e paralinguistica. Napoli: Liguori.
de Castro Moutinho, Lurdes & Coimbra, Rosa Lídia & Rilliard, Albert & Romano, Antonio.
- Mesure de la variation prosodique diatopique en portugais européen. Estudios de fonética experimentall 20. 33-55.
Cazade, Alain. 1999. De l’usage des courbes sonores et autres supports graphiques pour aider l’apprenant en langues. Apprentissage des Langues et Systèmes d’Information et de Communication, onlinee 2(2). 3-32.
Cheng, Victor Chi-Wa & Lau, Vincent King-Tang & Lam, Ringo Wai-Kit & Zhan, Tian-Jie & Chan, Pak-Kin. 2020. Improving English phoneme pronunciation with automatic speech recognition using voice chatbot. In Lee, Lap-Kei & U, Leong Hou & Wang, Fu Lee & Cheung, Simon K. S. & Au, Oliver & Li Kam Cheong (eds.), International Conference on Technology in Education, 88-99. Singapore: Springer.
Chun, Dorothy. 1998. Signal analysis software for teaching discourse intonation. Language Learning & Technologyy 2. 61-77.
Chun, Dorothy. 2002. Discourse Intonation in L2: From theory and research to practice. Amsterdam: Benjamins.
Colace, Francesco & De Santo, Massimo & Lombardi, Marco & Pascale, Francesco & Pietrosanto, Antonio & Lemma, Saverio. 2018. Chatbot for e-learning: A case of study. International Journal of Mechanical Engineering and Robotics Research 7(5). 528-533.
Cresti, Emanuela. 1999. Force illocutoire, articulation topic/comment et contour prosodique en italien parlé. Faits de languee 13. 168-181.
Crocco, Claudia. 2017. Everyone has an accent: standard Italian and regional pronunciation. In Cerruti, Massimo & Crocco, Claudia & Marzo Stefania (eds.), Towards a New Standard: Theoretical and Empirical Studies on the Restandardization of Italian, 89-117. Berlin/New York: Mouton de Gruyter.
Cruttenden, Alan. 1986. Intonation. Cambridge: Cambridge University Press.
De Bot, Kees. 1983. Visual feedback of intonation I: Effectiveness and Induced Practice Behavior. Language and Speech 26(4). 331-350.
De Iacovo, Valentina & Romano, Antonio. 2019. DataDriven intonation teaching: an overview and new perspectives. EL.LEEE, 8(2). 393-408.
De Marco, Anna & Sorianello, Patrizia & Mascherpa, Eugenia. 2014. L’acquisizione dei profili intonativi in apprendenti di italiano L2 attraverso un’unità di apprendimento in modalità blended learning. In De Meo, Anna & D’Agostino, Mari (a cura di), Varietà dei contesti di apprendimento linguistico, 189-210. Milano: AItLA
De Meo, Anna & Pettorino Massimo (eds.), 2012. Prosodic and Rhythmic Aspects of L2 Acquisition: The Case of Italian. Cambridge: Cambridge Scholar Publishing.
Delattre, Pierre. 1966. Les dix intonations de base du français, French Revieww 40. 1-14.
Delmonte, Rodolfo. 2009. Prosodic tools for language learning. International Journal of Speech Technology 12(4). 161-184.
Fernoagă, Vlad & Stelea George Alex & Gavrilă, Cristinel & Sandu, Florin. 2018. Intelligent education assistant powered by chatbots. The International Scientific Conference eLearning and Software for Education 2. 376-383.
LA VARIAZIONE PROSODICA IN ITALIANO 97
Appendice
Elenco delle domande e risposte utilizzate:
- Quale fra questi gruppi di opere è formato di sole opere italiane del Novecento? A. L’Orlando furioso, L’Iliade e L’Odissea. B. La divina commedia, Il fu Mattia Pascal e Lo Zibaldone. C. I promessi sposi, La Vita Nuova e La Gerusalemme liberata. D. Uno, nessuno e centomila, La coscienza di Zeno e Se questo è un uomo., , q
- Chiara ha bisogno di sapere l’ora, come fa? A. Scusi, ho lasciato l’orologio a casa, sa dirmi che ore sono?, g , B. Scusa, ho lasciato l’orologio a casa, per caso ha l’ora? C. Sa dirmi che ora sono per favore che ho lasciato l’orologio a casa? D. Mi scusi, ho lasciato l’orologio a casa, qual è il tempo oggi?
- Marco e Salvatore si sono messi d’accordo per andare a mangiarsi una pizza e Marco deve dare appuntamento a Salvatore, cosa NON gli dirà? A. Ciao Salvatore, allora ci troviamo alle 8 lì davanti? B. Ciao Salvatore, allora ci becchiamo alle 8 davanti alla pizzeria? C. Ciao Salvatore, allora ci incontriamo alle 8 lì? D. Ciao Salvatore, allora ci andiamo a fare una partita a calcio uno di questi giorni?, p q g
- Gianna vuole chiedere a Marta di comprare della frutta, cosa le dirà? A. Senti Marta, una domanda: ma a te piace la cassata? B. Senti Marta, stai uscendo? Se riesci a comprare della frutta, mi fai un favore., p , C. Senti Marta, mi sa che non ci sono più pesche. D. Senti Marta, che tu sappia, c’è ancora frutta in casa?
- In quale anno l’Italia è diventata una Repubblica? A. Nel giugno del 1950. B. Durante l’autunno del 1939. C. Tra il 1945 e il 1946. D. Il 18 marzo 1861.
- In quale giorno è scoppiata la Rivoluzione francese? A. Nell’anno 1789. B. Il 14 luglio 1789.g C. Nel marzo 1938. D. Nel 1914.
- L’espressione “avere le mani legate” vuol dire: A. Non riuscire a prendere qualcosa che si trova in alto in uno scaffale. B. Non avere nessuna possibilità di agire come si vorrebbe.p g C. Avere tempi ristretti e non riuscire ad arrivare in orario a un appuntamento. D. Fare di tutto senza essere all’altezza di una situazione.
- In quale di queste frasi il periodo ipotetico è utilizzato correttamente? A. Se vieni con me, ti portassi a mangiare una pizza. B. Se venissi con me, ti avrei portato a mangiare una pizza. C. Se verresti con me, ti porto a mangiare una pizza. D. Se fossi venuto con me, ti avrei portato a mangiare una pizza., p g p
98 VALENTINA DE IACOVO - MARCO PALENA
- Dov’è morto Giuseppe Garibaldi? A. Giuseppe Garibaldi è morto nell’isola di Caprera. B. Nel gennaio del 1882. C. Garibaldi è morto all’isola d’Elba. D. Quando aveva 75 anni.
- 1 + 2/3 equivale a: A. 4/4 + 4/ B. 1/6 + 3/ C. ¼ + 4/ D. 1/3 - 0,