¡Descarga ejercicios capitulo 1 y más Ejercicios en PDF de Psicología solo en Docsity!
CAPITULO 1.
¿Por qué hablamos del tipo de medida de las variables? El tipo de medida determina la técnica estadística con la que se estudian.
EJERCICIO:
Clasificar las variables como cuantitativas o categóricas :
Percepción subjetiva del dolor (de 0 a 100 puntos)- Cuantitativa
Grupo de tratamiento (experimental – control)-Nominal
Peso de los recién nacidos-Cuantitativa
Tiempo de reacción-Cuantitativa
Calidad percibida del estado de salud general-Cuantitativa
Rendimiento en el test de inteligencia Raven- Cuantitativa
Actitud hacia el aborto (en contra, indiferente, a favor)-Nominal
Nivel socioeconómico (bajo, medio, alto)-Nominal
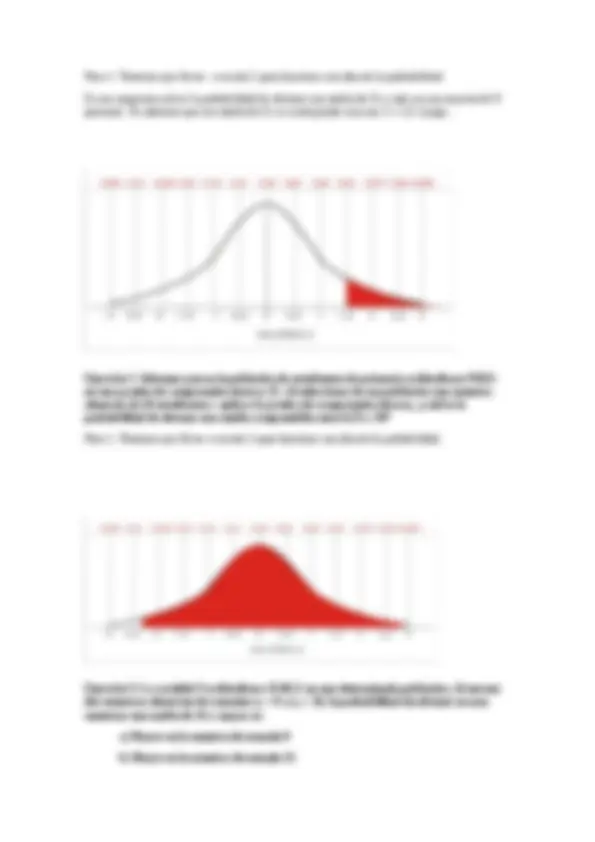
Por ejemplo : supón que obtienes una puntuación de 32 en una prueba de aptitud espacial.
¿Cómo interpretamos esta puntuación?
¿Cuál es la probabilidad de obtener una puntuación como la tuya o más alta entre el resto de puntuaciones?
La distribución de la prueba de aptitud espacial es N (20,6), o sea, la distribución de la prueba es normal con
Necesitamos tipificar la puntuación para transformarla en la N (0,1).
Respuesta: mi puntuación está 2 desviaciones típicas por encima de la media (Z = 2).
La probabilidad de obtener una puntuación Z=2 o mayor, es decir, P(Z ≥ 2), es 1 – P(Z ≤ 2) = 1
- 0,9772 = 0,0228. Lo que significa es que la probabilidad de tener una z mayor o igual que dos es 0’0228 y la probabilidad de tener una z menor o igual que 2 es 0’9772.
DISTRIBUCIÓN MUESTRAL DE LA MEDIA.
EJERCICIO: Sabiendo que la distribución de la población es N (20,6) en la prueba de aptitud espacial, ¿cuál es la probabilidad de que al extraer aleatoriamente una muestra de 36 personas de la población, la media de esa muestra esté por encima de 23 puntos?
Se está preguntando implícitamente por la distribución de la media.
La media coincide con la media de la población.
La distribución muestral de la media es:
Normal
Su media es μ
Su desviación típica es y se conoce como error típico
Luego tenemos que
La distribución muestral de la media de la prueba de aptitud espacial en muestras de 36 personas es:
¿Cuál es la probabilidad de que en una muestra al azar de 36 personas la media sea de 23 o mayor? Para eso conviene tipificar
P(Z ≥ 3) = 1 – P(Z ≤ 3) = 1 – 0,9987 = 0,
¿Y si la muestra fuera de 64 personas, cuál sería la probabilidad de encontrarnos una media de 23 o mayor?
¿Sería igual de probable que con la muestra de 36 personas, más probable o menos probable encontrarnos esa media de 23 puntos o mayor?
La distribución muestral de la media de la prueba de aptitud espacial en muestras de 64 personas es: La distribución típica es llamada error típico, a medida que aumentamos el tamaño muestral el error típico será más pequeño.
Calculamos la Z que se corresponde con una media de 23:
Conclusiones:
-Las distribuciones muestrales nos permiten ver la probabilidad de obtener un estadístico.
-Las distribuciones muestrales se ‘estrechan’ cuanto mayor es el tamaño de la muestra. O lo que es lo mismo, el error típico disminuye a medida que aumenta n.
Ejercicio 1. En la población general se sabe que la media en una escala de autoestima es 18 y la desviación típica 6. Si extraemos una muestra de 9 personas, ¿cuál es la probabilidad de obtener una media muestral de 21 o mayor?
c) Exactamente igual en las dos
Para responder se puede calcular la Z que se corresponde con en la muestra n (^) 1 = 9 y n (^) 2 = 16 y ver en cuál de ellas tenemos una Z más extrema.
Luego es más probable encontrar una media de 15 o mayor en la muestra n (^) 1 = 9, dado que su Z es más pequeña.
Ejercicio 4: En los años 50 del siglo pasado se realizaron pruebas masivas para medir el CI. La distribución del CI poblacional era N (100,15).
Hoy, un grupo de psicólogos sospecha que la media puede haber cambiado. Para ello selecciona una muestra aleatoria de la población de tamaño 25 y obtiene una media de 109.
¿Qué opinas sobre esta creencia que tienen los psicólogos y por qué?
Como en el resto de ejercicios, tenemos que calcular cuál es la Z que se corresponde con.
Haber encontrado una media de 109 se corresponde con una Z = 3. Una Z ≥ 3 es muy improbable. Luego parece que los psicólogos tienen razón: no se puede sostener que la media de CI sea 100 actualmente.
DISTRIBUCIÓN MUESTRAL DE LA PROPORCIÓN.
Ejemplo: en un examen de 20 preguntas tipo test con 4 alternativas, ¿cuál es la probabilidad de que respondiendo completamente al azar un estudiante acierte 10 ó más preguntas?
Como cada pregunta tiene 4 alternativas de respuesta, la probabilidad de acertar cada pregunta es de 1/4 : π 1 = 0,25. Como son 20 preguntas n = 20. Si acertamos 10 preguntas P (^) 1 = 10/20 = 0,5.
La probabilidad de aprobar es 0,005.
¿Y si el examen fuese de 40 preguntas en lugar de 20? ¿Cómo sería la probabilidad de aprobar, mayor, igual o menor que en el de 20 (suponemos igualmente que contestamos las 40 preguntas totalmente al azar)?
Más baja aún en el examen de 40 preguntas:
Ejercicio 1. Los datos recogidos en los últimos años indican que el 65% de los estudiantes universitarios muestra una actitud favorable hacia la eutanasia.¿Cuál es la probabilidad de encontrar en una muestra aleatoria de 20 universitarios más de 15 con actitud favorable?
Utilizaremos la aproximación a la normal.
Por lo que necesitamos conocer P 1 , π (^) 1 y σ P
P 1 es (más de 15 a favor entre 20 universitarios) =16/20 = 0,80.
π 1 es la proporción en la población 0,65.
σ P1 es el error típico de la proporción:
Por lo tanto, la probabilidad de encontrarnos con 16 o más universitarios a favor de la eutanasia entre los 20 muestreados es :
ESTIMACIÓN POR INTERVALOS DE LA MEDIA.
Ejemplo: una muestra de 100 aleatoria de pacientes con depresión obtienen una media en una prueba de autoestima de 15. Sabiendo que σ = 4, ¿entre qué límites cabe esperar la media de autoestima entre la población de pacientes depresivos? Queremos una confianza del 95%.
1 – α = 1 – 0,05 = 0,
Límites en la N(0,1) que encierran un área de 0,95. Son Zα/2 = -1,96 y Z (^) 1-α/2 = 1,
Error típico de la media:
Error máximo:
Calculamos los límites del intervalo:
Ejercicio 1. Cont. Con los datos del problema anterior, imagina ahora que tu muestra aleatoria de universitarios era de 100 personas.
Sin hacer los cálculos, el intervalo de confianza, ¿será más amplio o más estrecho que con 36 personas? ¿Por qué?
Respuesta: Con 100 personas la precisión es más alta que con 36. Es debido a que el error típico de la media , es menor con 100 personas. Por lo tanto, la amplitud del intervalo será menor con 100 personas.
Aunque no se pide en el ejercicio, los límites del intervalo serían en este caso:
Ejercicio 2. ¿Para qué me sirve poder calcular los intervalos de confianza?
Supongamos que vuestro profesor de memoria os dice que la memoria de trabajo tiene media poblacional, μ, igual a 7 y desviación típica poblacional, σ, igual a 1.
Este tipo de memoria se mide evaluando la capacidad, por ejemplo, para el recuerdo de dígitos.
Un grupo plantea como investigación si en la población universitaria se cumple que la media poblacional es μ=7. Para ello seleccionáis una muestra aleatoria de 25 universitarios, les pasáis la prueba de dígitos y obtenéis una media muestral de 8,2.
¿Utilizando una confianza de 0,95, qué concluiríais en vuestra investigación?
N = 25, α = 0,05, σ (^) Y = 1 y
- Nivel de confianza que queremos.
1 – α = 1 – 0,05 = 0,
Límites en la N(0,1) que encierran un área de 0,95. Son Zα/2 = -1,96 y Z (^) 1-α/2 = 1,
Error típico de la media
Error máximo:
Calculamos los límites del intervalo:
Conclusión: En el trabajo (informe científico) se podría informar de la siguiente forma.
“Los datos muestrales (N=25) proporcionaron una media de 8,2 dígitos memorizados, IC 95% [7,808; 8,592], de forma que se puede afirmar que en la población universitaria la media de memoria de trabajo es superior a 7.”
Ejercicio. Un grupo de estudiantes de psicología intenta averiguar entre la población de estudiantes de la UAM qué porcentaje piensa votar al PP en las próximas elecciones. Selecciona aleatoriamente en el campus a una muestra de 80 estudiantes y obtiene que 20 de ellos votarán al PP. ¿Entre qué valores puede estimarse que se encuentra la verdadera proporción de votantes del PP entre los estudiantes de la UAM (1 – α = 0,95)?
N = 80, α = 0,05 y P = 20/80 = 0,
- Nivel de confianza deseado para la estimación:
1 – α = 1 – 0,05 = 0,
Límites en la N(0,1) que encierran un área de 0,95. Son Zα/2 = -1,96 y Z (^) 1-α/2 = 1,
Error típico de la proporción:
Error máximo:
Calculamos los límites del intervalo:
Conclusión :
“Los datos muestrales (N=80) proporcionaron una proporción de votantes del PP de 0,25, IC 95%[0,155; 0,345], de forma que se puede afirmar con una confianza del 95% que la proporción de votantes del PP en la población universitaria está entre 0,155 y 0,345.”
CON T DE STUDENT
Ejemplo: en una muestra de 16 pacientes de depresión obtenemos una media en una escala de ansiedad de 25 puntos y una desviación típica de 8. ¿Entre qué límites cabe esperar que se encuentre la media poblacional? (α = 0,05)
- α = 0,05 y 1 - α = 0,95.
- Tenemos que
- Error típico:
- El error máximo:
- (^) Límites
ESTIMACIÓN POR INTERVALOS DE LA PROPORCIÓN.
Ejemplo: un psicólogo clínico comienza a aplicar una terapia nueva en pacientes con trastorno obsesivo compulsivo. De una muestra aleatoria de 20 pacientes consigue que 12 se
5. Zona crítica:
Como el contraste es bilateral partimos la distribución muestral en dos zonas de rechazo que dejen respectivamente una probabilidad de α/2 = 0,05/2 = 0,025.
Según las tablas de la normal, la Z que acumula una probabilidad de 0,025 es -1,96 y la que acumula una probabilidad de 0,975 es +1,96.
Por lo tanto, rechazaré H (^) 0 si mi estadístico Z cae en la zona de rechazo (zona crítica), esto es, si Z ≤ -1,96 o si Z ≥ 1,96.
6. Decisión:
Como Z = -1,68 cae en la zona 1 – α debemos mantener H (^) 0 ( p > α )
Ejercicio 2. En la década pasada se estudió que la población de adolescentes de entre 16- años dedicaban a las redes sociales en promedio 2 horas diarias. Se sospecha que hoy el auge de las redes sociales ha perdido importancia y que el tiempo diario dedicado es menor. Para ello, un equipo de psicólogos sociales encuesta a 25 adolescentes seleccionados aleatoriamente de entre 16-18 años y obtienen una media de 1,5 horas ¿Qué concluirá el equipo de psicólogos con un nivel de confianza de 0,95?
(supóngase que σY = 1)
N = 25 personas; σY = 1 ; ; α = 0,
- Hipótesis:
H (^) 0 :
H (^) 1 :
- Supuestos:
La muestra aleatoria de 25 personas se extrae aleatoriamente
Estadístico del contraste:
Distribución muestral del estadístico Z.
Z tiene una distribución muestral conocida: la N(0,1)
- Regla de decisión
Como se trata de un contraste unilateral izquierdo delimito la zona de rechazo a la izquierda de la distribución de Z.
- Regla de decisión
Ya tengo el punto crítico a partir del cual rechazo H (^) 0 : Z = -1,65, por lo tanto rechazaré H (^) 0 si mi estadístico Z ≤ -1,65 y mantendré H (^) 0 si Z > -1,65.
- Decisión
Puesto que mi estadístico del contraste, Z, toma un valor de -2,5, menor de -1,65, rechazo H (^) 0 y concluyo que la media poblacional de horas dedicadas a las redes sociales, efectivamente, es menor de 2 horas entre los adolescentes.
Ejempl o: un equipo de epidemiología quiere saber si la proporción de fumadores en la población de 16 a 24 años es del 35%. Para ello seleccionan una muestra aleatoria de 64 jóvenes y comprueban que 16 de ellos fuman. A la luz de los datos, ¿podemos mantener la hipótesis nula de que la proporción de fumadores entre los jóvenes es del 35%?
Utilizamos un nivel de significación, α, de 0,05.
- Hipótesis: contraste bilateral
- Supuestos:
Tenemos una muestra aleatoria de 64 observaciones.
- Estadístico del contraste
- Distribución muestral
Z se aproxima a N (0,1)
- Zona crítica (Regla de decisión):
Como el contraste es bilateral partimos la distribución muestral en dos zonas de rechazo que dejen respectivamente una probabilidad de α/2 = 0,05/2 = 0,025.
Según las tablas de la normal, la Z que acumula una probabilidad de 0,025 es -1,96 y la que acumula una probabilidad de 0,975 es +1,96.
Ejercicio 5. Supongamos que hacemos tres contrastes de hipótesis unilateral derechos con α = 0,05. En el primero de ellos obtenemos un nivel crítico p = 0,98, en el segundo p = 0,07 y en el tercero p = 0,01.
¿Con qué distribuciones muestrales se corresponde el primer contraste, el segundo y el tercero?
p=0’98 B
p=0’07 A
p=0’01 C
Ejercicio 6. Un estadístico V tiene la función de probabilidad acumulada que muestra la tabla. Llevado a cabo un contraste unilateral izquierdo con una determinada muestra obtenemos para el estadístico V un valor de –1.
V -1 -0,5 0 0,5 1 1,5 2
F(V| H 0 ) 0,03 0,05 0,37 0,65 0,90 0,97 1
Lo que aparece en la segunda fila es la probabilidad de lo que queda a la izquierda, lo que acumula.
a. La regla de decisión podría ser rechazar H (^) 0 cuando V es ≤? Rechazamos cuando tenemos una V que vale -0,5 o menos, porque si V vale -0,5 el nivel crítico ( lo qu queda a la izquierda) es -0,
b. ¿Qué decisión debe tomarse sobre H (^) 0? ¿Por qué? Si obtenemos una V de -1 se rechaza porque el valor que queda está dentro de la zona de riesgo, ya que esta está delimitada por los valores que queden a la izquierda de -0,
c. ¿Cuánto vale el nivel crítico p? 0’
Ejercicio 7. Un investigador afirma que, entre los estudiantes universitarios, ellas fuman más que ellos. Tras efectuar una encuesta, ha comparado la proporción de fumadoras con la proporción de fumadores ( H 0 : π (^) ellas ≤ π (^) ellos ; H (^) 1 : π (^) ellas > π ellos ) y ha obtenido para el estadístico del contraste, un valor T = 2,681. La siguiente tabla ofrece la función de distribución (probabilidades acumuladas) de algunos de los valores del estadístico T :
T -0,539 0,000 0,539 1,356 1,782 2,179 2,
F(T| H 0 ) 0,300 0,500 0,700 0,900 0,950 0,975 0,
Los valores compatibles con la hipótesis nula se encuentran a la derecha de la distribución. Rechazamos a partir de T=1,782 porque como α es 0,05 lo que deja atrás es 0,95 y esta probabilidad acumulada corresponde a la esta T.
Con α = 0,
a. ¿Puede afirmarse que los datos confirman la hipótesis del investigador? ¿Por qué? No, porque el 2,681 está en la zona de rechazo, rechazamos la hipótesis nula.
b. ¿Cuánto vale el nivel crítico p****? 1-0,990=0,
c. ¿A partir de qué nivel de significación (α) podría rechazarse H 0? A partir del nivel crítico, 0,01. Si el nivel crítico coincide con α rechazamos.
Ejercicio 8. Un terapeuta afirma que una determinada terapia consigue recuperaciones aceptables en más del 80% de los pacientes tratados. Un colega suyo piensa que la proporción de recuperaciones aceptables es menor que el 80%. Ambos realizan un estudio para contrastar sus respectivas hipótesis con α = 0,05.
a. ¿Qué hipótesis estadísticas debe plantear cada terapeuta?
T1: H0: media <0,80 T2: H0: media >0,
H1: media > 0,80 H1:media < 0,
b. Al contrastar su H (^) 0 el primer terapeuta obtiene un nivel crítico p = 0,818. ¿Qué decisión debe tomar? ¿Por qué?
c. Al contrastar su H (^) 0 el segundo terapeuta obtiene un nivel crítico p = 0,002. ¿Qué decisión debe tomar? ¿Por qué?
d. ¿Cuál de los dos terapeutas tiene razón?, ¿tienen razón los dos?, ¿no tiene razón ninguno de los dos? El segundo consigue falsar la hipótesis nula.
IMPORTANTE.
Cuando rechazamos una H (^) 0 decimos que ésta es falsa y que, por tanto, H (^) 1 se considera verdadera.
Ahora bien, cuando mantenemos H 0 decimos que los datos son compatibles con la hipótesis nula, NO decimos nunca que la hipótesis nula sea cierta.
Ejercicio 10. La siguiente tabla muestra las funciones de probabilidad acumuladas del estadístico Z bajo H (^) 0 y bajo una determinada H 1.
Z -1,96 -1,645 -1 0 1 1,645 1,96 2
f( W | H (^) 1 ) 0,05 0,25 0,30 0,20 0,10 0,10 0
Rechazaremos cuando W valga -1 o -2.
Si establecemos como regla de decisión “Rechazar H (^) 0 si W toma un valor menor que 0”; mantenerla en caso contrario”,
a. ¿Cuál es la probabilidad de mantener H (^) 0 siendo falsa (β)?, ¿cuánto vale la potencia del contraste (1 – β)? Sumamos 0’00 y 0’03, y la probabilidad será 0’03. El nivel de confianza es cuando mantenemos un hipótesis nula que es verdadera, eso ocurre cuando W vale 0,1,2,3 y 4 lo que nos da 0’97.
b. ¿Cuál es la probabilidad de rechazar H (^) 0 siendo verdadera (α)? Tenemos que sumar los dos valores de –1 y de -2 y la solución es 0’
Ejercicio 12. Sea un contraste unilateral derecho con α = 0,05. Se muestran las probabilidades de un estadístico, n 1 , bajo H (^) 0 y H (^) 1.
n 1 0 1 2 3 4
f(n 1 |H 0 ) 0,130 0,345 0,345 0,154 0,
f(n 1 | H (^) 1 ) 0,026 0,154 0,345 0,345 0,
Lo primero que tenemos que hacer es saber a partir de qué valor se rechaza H0, tenemos que mirar hacia la derecha. Con α=0’05. Sólo rechazaremos H0 cuando n1 tome un valor igual a 4 porque si n1=3 es mayor que α. Rechazamos cuando P (nivel crítico, probabilidad) es menor que α.
Dato: no son probabilidades acumuladas, son discretas.
a. ¿Cuál será la decisión sobre H (^) 0 si n 1 = 3? Mantenemos H0, en nivel crítico P es 0’ +0’26=0’
b. ¿Qué tipo de error se podría estar cometiendo con esta decisión? Error de tipo 2, que la H0 sea falsa y la haya mantenido.
c. ¿Cuánto vale la probabilidad de cometer ese error? Como tendríamos que mantener H0 con 0,1,2,3 tenemos que sumar todas las probabilidades.
d. ¿Cuánto vale la potencia del contraste? 0’130 (probabilidad de que n1 sea 4)
Todo esto sirve para cuando quiero rechazar una hipótesis pero H1 es pequeño, las curvas se solapan mucho, se puede meter la pata.