


MODELO MULTIVARIANTE
Modelo con varias variables explicativas
GRADO EN ADMINISTRACIÓN Y DIRECCIÓN DE EMPRESAS
ECONOMETRÍA EMPRESARIAL









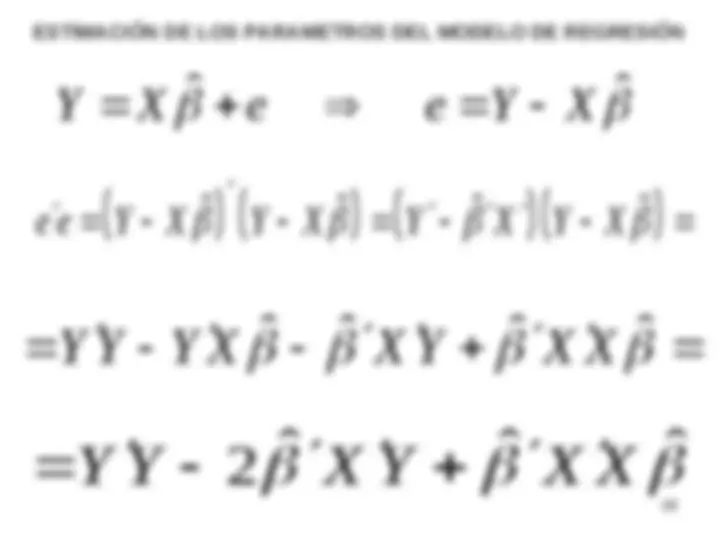
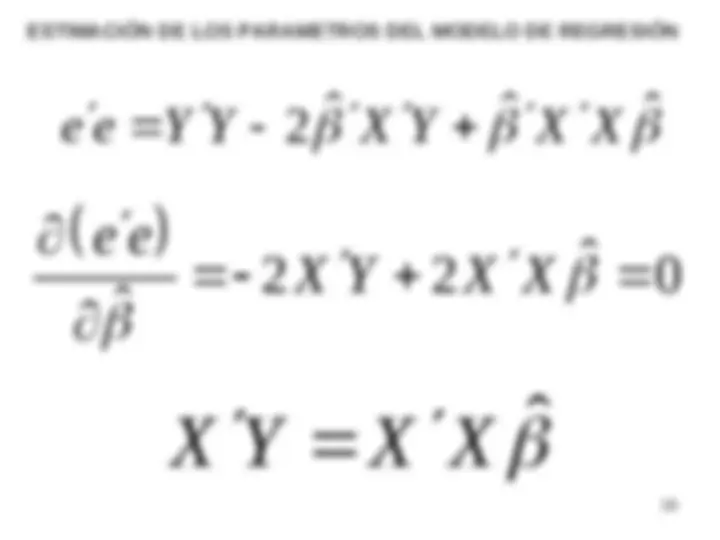
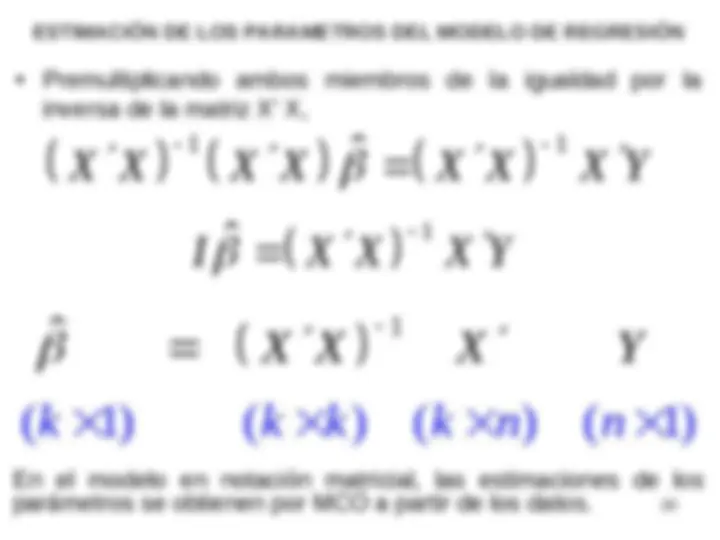
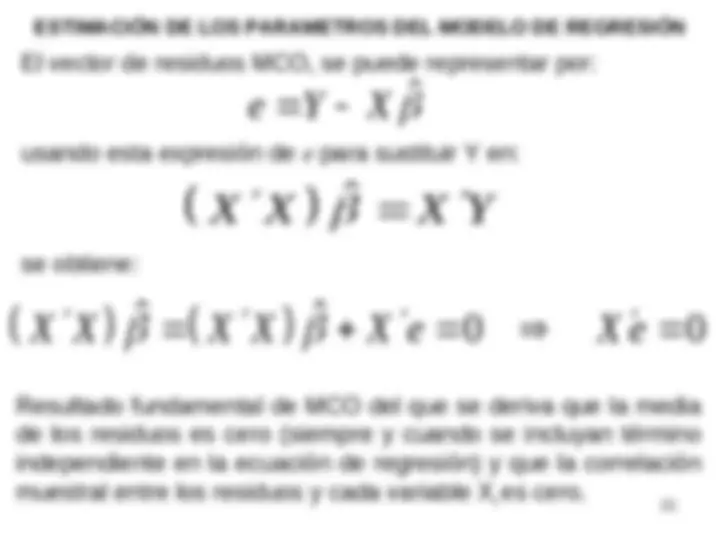














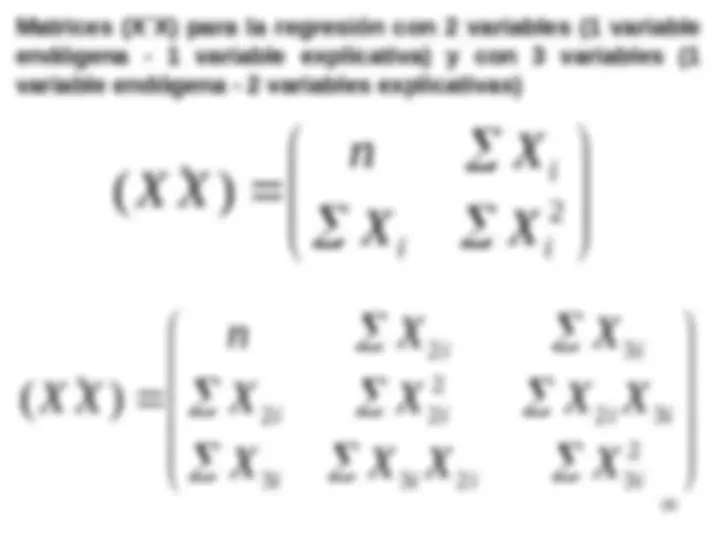

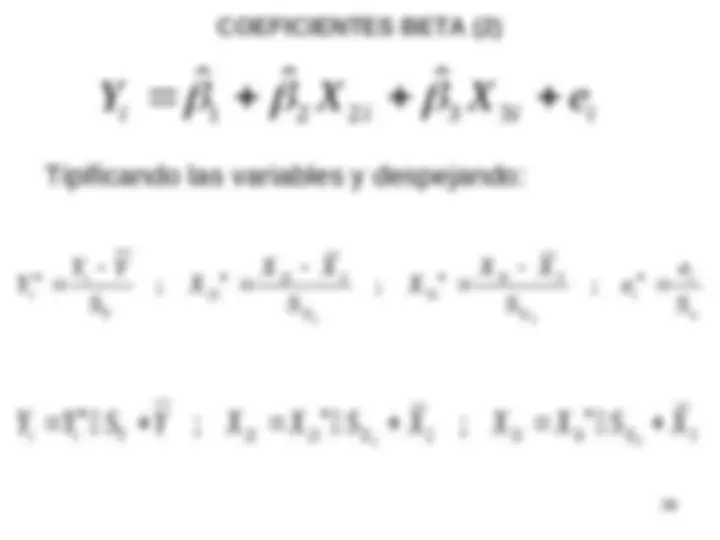








































Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Asignatura: econometria, Profesor: vicente Rodriguez Sosa, Carrera: Administración y Dirección de Empresas, Universidad: US
Tipo: Apuntes
1 / 77

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
GRADO EN ADMINISTRACIÓN Y DIRECCIÓN DE EMPRESAS
ECONOMETRÍA EMPRESARIAL
1 1 2 2 3 3
...
i i i i k ki i
Y X X X X
Con esta nomenclatura el nº de variables explicativas es k-1.
β 1
se denomina intersección, ordenada en el origen o
constante de regresión.
2
a β k
son los coeficientes parciales de la pendiente,
pendientes de la regresión o coeficientes de regresión
parcial.
Una forma alternativa de expresar esta ecuación es:
en la que X 1i
= 1, para i = 1, 2, …, n.
...
Y X X X
SISTEMA DE N ECUACIONES CON K INCÓGNITAS EN NOTACIÓN
MATRICIAL
1 11 21 31 1 1 1
2 12 22 32 2 2 2
1 2 3
...
...
... ......................... ... ...
...
( 1) ( ) ( 1) ( 1)
k
k
n n n n kn k n
Y X X X X
Y X X X X
Y X X X X
Y X
n n k k n
(^)
SISTEMA DE ECUACIONES EN NOTACIÓN MATRICIAL
1
para designar a la i-ésima
observación de la variable X k
supone que los subíndices de la matriz X
están en un orden contrario al habitual (1º subíndice para la fila y 2º
para la columna).
HIPOTESIS SOBRE LAS PERTURBACIONES
2
i
i
2
2
Para datos transversales se habla de no correlación por
parejas, para datos temporales se denomina supuesto de no
autocorrelación.
siendo i ≠ j para i, j = 1, 2, …, n.
, , 0
i j i j
Cov ^ ^ E ^
MATRIZ DE VARIANCIAS-COVARIANCIAS DE LAS PERTURBACIONES
La consideración conjunta de las hipótesis 2ª y 3ª hace que:
2
1 1 2 1 1
2
2 2 1 2 2
1 2
2
1 2
n
n
n
n
n n n
2
2
1 1 2 1
2 2
(^2 1 2 2 )
2
2
1 2
n
n
n n n
2
CONSECUENCIAS DE LAS HIPOTESIS SOBRE LAS PERTURBACIONES
Las distribuciones de las Y i
son Normales, igual que en el
caso del modelo de regresión simple, siendo sus medidas:
y sus varianzas:
y dada la independencia de las perturbaciones,
por lo que el vector columna de las Y i
seguirá una distribución
Normal Multivariante cuyo vector de medidas estaría
formado por los valores esperados de las Y i
y su matriz de
variancias y covariancias sería
2
, , 0
i j i j
Cov Y Y ^ ^ E ^ i j
1 2 2
....
i i k ki
E Y X X
10
2
2 2
i i i i
Var Y E Y E Y E
HIPÓTESIS SOBRE LAS VARIABLES
5ª) Este supuesto hace referencia al método de extracción de
la muestra. Si las observaciones se extraen mediante muestreo
aleatorio simple de una única y gran población,
i
i
), para i = 1, 2,…, n, son independientes e
idénticamente distribuidas (i.i.d)
Es decir, las n-tuplas de valores (X
1i
2i
i
), presentan la
misma distribución y se distribuyen además de forma
independiente de una observación a otra, son i.i.d.
Este supuesto es razonable para muchos sistemas de elección
de datos, aunque no todas las técnicas de selección de la
muestra proporcionan observaciones i.i.d. de las variables del
modelo. Así, para un método de selección de la muestra
empleado con frecuencia,
HIPÓTESIS SOBRE LOS PARÁMETROS
HIPÓTESIS SOBRE LOS DATOS
Es decir, observaciones con valores X
i
o Y
i
, o ambos, muy lejos
del ámbito habitual de los datos, son poco probables.
Esto se expresa matemáticamente suponiendo que los
momentos de cuarto orden de X e Y existen y son finitos. En
otros términos: que X e Y tiene curtosis finita.
4 4
0 [ ] 0 [ ]
i i
E X y E Y
Es utilizado para justificar matemáticamente las aproximaciones
para muestras grandes de los estadísticos MCO empleados en
los contrastes. En casos de alta frecuencia de valores atípicos y,
dada la sensibilidad a ellos de los estimadores MCO, se pueden
calcular estimadores de mínima desviación absoluta (MDA), más
eficientes y que proporciona inferencias más fiables. 14
INTERPRETACIÓN DE LOS PARÁMETROS DEL MODELO
1
i
2
k
i
2
k
2
k
ESTIMACIÓN DE LOS PARAMETROS DEL MODELO DE REGRESIÓN
2
2
1 2 2
ˆ ˆ ˆ
...
i i i k ki
e Y X X sea minima
1
2
2 2 2 2
1 2 1 2
... .. ...
..
n n i
n
e
e
e e e e e e e e e
e
ESTIMACIÓN DE LOS PARAMETROS DEL MODELO DE REGRESIÓN
ˆ
2 2 0
ˆ
e e
X Y X X
ˆ
X Y X X
ˆ ˆ ˆ
e e Y Y 2 X Y X X
ESTIMACIÓN DE LOS PARAMETROS DEL MODELO DE REGRESIÓN
inversa de la matriz X’ X,
1 1
ˆ
X X X X X X X Y
I X X X Y
20
1
( 1) ( ) ( )
ˆ
k k k k ( 1)
X X X
n
Y
n
En el modelo en notación matricial, las estimaciones de los
parámetros se obtienen por MCO a partir de los datos.