



Regressão Linear (II)
Prof. Danilo Silva
EEL7514/EEL7513 - Tópico Avançado em Processamento de Sinais:
Introdução ao Aprendizado de Máquina
EEL / CTC / UFSC

















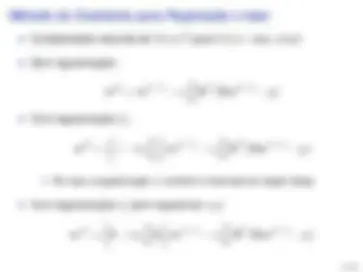














Estude fácil! Tem muito documento disponível na Docsity

Ganhe pontos ajudando outros esrudantes ou compre um plano Premium

Prepare-se para as provas
Estude fácil! Tem muito documento disponível na Docsity
Prepare-se para as provas com trabalhos de outros alunos como você, aqui na Docsity
Encontra documentos específicos para os exames da tua universidade
Prepare-se com as videoaulas e exercícios resolvidos criados a partir da grade da sua Universidade
Responda perguntas de provas passadas e avalie sua preparação.
Ganhe pontos para baixar
Ganhe pontos ajudando outros esrudantes ou compre um plano Premium
Este documento aborda a revisão de regressão linear, método do gradiente, normalização de atributos e introdução à otimização numérica, incluindo problemas de otimização sem restrições, convexidade e exemplos de métodos de otimização. Além disso, é apresentado o método do gradiente para regressão linear e a escolha da taxa de aprendizado.
Tipologia: Slides
1 / 43

Esta página não é visível na pré-visualização
Não perca as partes importantes!
Prof. Danilo Silva
EEL7514/EEL7513 - Tópico Avançado em Processamento de Sinais:
Introdução ao Aprendizado de Máquina
EEL / CTC / UFSC
I (^) Regressão linear: revisão
I (^) Método do gradiente
I (^) Normalização de atributos
I (^) Modelo de regressão linear:
ˆy = f (x) = w 0 + w 1 x 1 + · · · + wnxn = w
T x
onde
I (^) y ∈ R é o valor-alvo do qual yˆ ∈ R é uma predição
I (^) x =
[ 1 x 1 · · · xn
]T ∈ R
n+ é o vetor de atributos
I (^) w =
[ w 0 w 1 · · · wn
]T é o vetor de parâmetros
I (^) Conjunto de treinamento D = {(x(1), y(1)),... , (x(m), y(m))}
organizado em uma matriz de projeto e um vetor de rótulos
— (x
(1) )
T —
. . .
— (x
(m) )
T —
e^ y^ =
y
(1)
. . .
y
(m)
I (^) Função custo:
J(w) =
m
∑^ m
i=
(w
T x
(i) − y
(i) )
m
‖Xw − y‖
2
I (^) Gradiente:
∇J(w) =
m
T (Xw − y)
I (^) Solução ótima (equação normal):
w = (X
T X)
− 1 X
T y
I (^) Nem todas as funções custo admitem solução analítica
I (^) Ex: regularização 1 , perda 1 (MAE), outras perdas
I (^) Calcular XT^ X pode ser computacionalmente custoso para n muito
grande: a ordem de complexidade (em número de operações) é O(mn
2 )
I (^) Solução: métodos iterativos de otimização
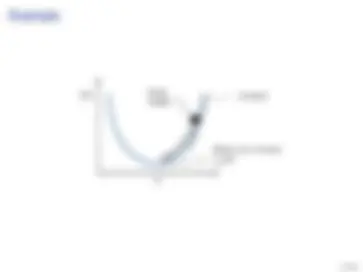
I (^) Se J(w) é uma função convexa, então todos os pontos estacionários
são mínimos globais (i.e., a condição de 1
a ordem é suficiente)
I (^) Uma função é convexa se todo segmento de reta conectando dois
pontos no gráfico da função situa-se inteiramente acima da função
I (^) O gradiente indica a tangente, enquanto a hessiana indica a curvatura
I (^) Ex:
J(w) =
1 m
‖Xw − y‖
2
1 m
‖w‖
2
∇J(w) =
2 m
XT^ (Xw − y) + λ
2 m
w
2 J(w) =
2 m
T X + λ
2 m
J(w) =
w
T Qw, Q = Q
T =⇒ ∇
2 J(w) = Q
I (^) Os autovalores da hessiana estão associados ao grau de curvatura