Baixe Rna com MatLab em formato de código e outras Manuais, Projetos, Pesquisas em PDF para Computação Paralela, somente na Docsity!
Redes Neurais para Inferência Estatística
- F E A / U S P Ju n/ 2 00 2 Renato Vicente∗
Programa
- Introdução: Redes Neurais, Matlab e Netlab
- Algoritmos de Otimização
- Estimação de Densidades de Probabilidade
- Redes Neurais com uma Camada
- Redes Neurais Multicamada
- Amostragem
- Técnicas Bayesianas
Opcionalmente:
- Radial Basis Functions
- Redução Dimensional e Visualização de dados
- Processos Gaussianos
Referências Básicas:
- (^) Using Matlab, The MathWorks Inc. (2000);
- (^) Bishop, C.M., Neural Networks for Pattern Recognition, Oxford University Press, Oxford, 1995;
- (^) Nabney, I.T., Netlab: Algorithms for Pattern Recognition, Springer, London, 2002.
∗ (^) [email protected]
Introdução: Redes Neurais, Matlab e Netlab
Redes Neurais
Rede Neural é um nome fantasia para modelos de inferência multidimensionais e não- lineares. O grande apelo destes modelos está em sua capacidade de “aprender”, generalizar ou extrair regras automaticamente de conjuntos de dados complexos.
No caso mais simples, temos um conjunto de pares entrada-saída D = {( x (^ n^ )^ , t (^ n^ ))} p n = 1 e
queremos modelar a função ˆ t^ = y = y ( , x w )que produz melhores estimativas para pares fora do conjunto D , dados vetores x. Este problema é denominado regressão. A Rede Neural consiste simplesmente de uma escolha particular para a família de funções y ( x w , )parametrizada por w , denominados pesos sinápticos.
A importância das Redes Neurais neste contexto está no fato delas representarem um esquema bastante genérico para a representação de famílias de funções não-lineares com várias variáveis de entrada e saída e controladas por um certo número de parâmetros ajustáveis.
Há uma série de famílias, ou arquiteturas, clássicas para Redes Neurais que são representadas graficamente.
Perceptron Linear Perceptron N ã o -line ar
R ede M u lticam ad a
1 0 1 1
n N l j j l j
y g u g w x w = =
(^) = (^) (^) +
0 1
N j j j
y g w x w
(^1) x
0 1
N j j j
y w x w
(^1) x
Matlab
Matlab (M atrix Labora tory ) é uma linguagem para computação científica com estrutura otimizada para a realização de operações com matrizes. O ambiente Matlab é composto por uma série de funções pré-definidas para cálculo, leitura e escrita de arquivos e visualização. Este conjunto de funções pode ser facilmente extendido por toolboxes dedicadas. Há toolboxes para finanças, tratamento de sinais, econometria e redes neurais.
Para ilustrar a forma como matrizes podem ser tratadas pelo Matlab utilizamos o quadrado mágico de Dührer que é utilizado como exemplo no G et Start que acompanha o software. Na linha de comando do Matlab entramos:
> A = [16 3 2 13; 5 10 11 8; 9 6 7 12; 4 15 14 1]
A = 16 3 2 13 5 10 11 8 9 6 7 12 4 15 14 1
Após este comando a matriz A fica armazenada no W orkspace do Matlab conforme ilustrado abaixo.
As propriedades do quadadro mágico podem ser analisadas utilizando funções do Matlab. Por exemplo, a função abaixo soma cada uma das linhas da matriz A.
> sum (A)
ans = 34 34 34 34
Na ausência de definição de variável de saída o Matlab aloca o resultado no W orkspace sob o nome a ns. Assim ao entrarmos > ans
ans = 34 34 34 34
Se quisermos somar as colunas ao invés das linhas temos que transpor a matriz A, isso feito simplesmente pelo comando
>A'
ans = 16 5 9 4 3 10 6 15 2 11 7 14 13 8 12 1
Assim podemos realizar a soma das colunas entrando
>sum(A')'
ans = 34 34 34 34
Novamente o resultado é 34. Podemos também calcular a soma da diagonal, ou traço, de duas formas:
> diag (A)
ans = 16 10 7 1
O Matlab possui uma função específica para a criação de quadrados mágicos de qualquer dimensão, esta função é
> B=magic(4)
B = 16 2 3 13 5 11 10 8 9 7 6 12 4 14 15 1
É possível reordenar as colunas de B para reobtermos A utilizando o comando
> B(:,[1 3 2 4])
ans = 16 3 2 13 5 10 11 8 9 6 7 12 4 15 14 1
Netlab
O Netlab é uma toolbox para Redes Neurais para Matlab disponibilizada gratuitamente no site do Neural Computing Research Group da Univerisdade de Aston (www.ncrg.aston.ac.uk). Esta toolbox toran a implementação de modelos baseados em Redes Neurais muito simples. Os códigos produzidos em Matlab podem então ser convertidos em executáveis utilizando o M atlab Co mpi ler. Como um primeiro contato com o Netlab escreveremos sua versão para o clássico "H ello W orld ".
Começamos por gerar de um conjunto de dados fictícios para treinamento de nossa Rede Neural. Para isso vamos supor que a função que queremos inferir é f ( x ) = sin (2 πx ). No entanto, só temos acesso a uma versão corrompida por ruído gaussiando desta função assim, nosso conjunto de dados é "gerado" da seguinte forma:
sin(2 )
n n n n
t x
N
onde N(0,1) é uma distribuição normal com média nula e variância unitária.
No Matlab teremos
1 x=[0:1/19:1]'; 2 ndata=size(x,1); 3 t=sin(2pix) + 0.15*randn(ndata,1);
Aqui utilizamos alguns recursos novos. Utilizamos ao final de cada linha ";" , esta instrução faz com que o Matlab omita resultados intermediários dos cálculos sendo executados. A primeira instrução gera um vetor coluna x com 20 dimensões contendo números de 0 a 1 em intervalos de 1/19. Na linha 2 utilizamos a função size(x, 1 ) para obtermos o tamnho em número de linhas do vetor coluna x, assim, se entrarmos:
> size(x)
ans = 20 1
Ou seja, o vetor x possui 20 linhas e 1 coluna, size(x, 1 ) nos dá o número de linhas, enquanto size(x, 2 ) nos dá o número de colunas. Na linha 3 utilizamos a função randn(linhas, cols) para gerarmos um vetor de números aleatórios independentes com distribuição gaussiana com média nula e variância unitária. De forma genérica esta instrução pode ser empregada pra gerar matrizes aleatórias de qualquer tamanho.
>ran dn(5,5)
ans = 1.3808 0.3908 -1.3745 -1.3454 -0. 1.3198 0.0203 -0.8393 1.4819 -0. -0.9094 -0.4060 -0.2086 0.0327 -0. -2.3056 -1.5349 0.7559 1.8705 -0. 1.7887 0.2214 0.3757 -1.2090 -0.
No Matlab, podemos visualizar o vetor t e a função original utilizando:
> plot(x,sin(2pix),x,t,'k+');
-1.5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
-0.
0
1
Gerado nosso conjunto fictício de dados, podemos definir uma arquitetura de rede para utilizarmos na inferência. Assumiremos aqui que uma Rede Neural Multicamada com 3
5 options=foptions;
A seguir personalizamos algumas destas opções:
6 options(1) = 0;
Este comando evita que os algoritmos de otimização exibam na tela a evolução passo a passo da função custo sendo minimizada.
7 options(14) =100;
Esta instrução limita em 100 passos os ciclos de otimização. Agora podemos treinar nossa rede utilizando a função ne topt do Netlab:
8 [net, options] = netopt(net, options, x, t, 'scg');
Warning: Maximum number of iterations has been exceeded
A função netopt otimiza os parâmetros da rede definida pela estrutura n et, utilizando as opções de otimizador defindas em options e utilizando os dados de entrada contidos no vetor x e de saída contidos no vetor t. O último argumento em netopt especifica o tipo de algoritmo a ser utilizado na otimização, no exemplo, 's cg' significa scaled gradient. A função retorna uma mensagem de aviso indicando que a otimização foi terminada devido ao limite de 100 passos de otimização.
Neste momento já obtivemos no W orkspace do Matlab uma estrutura net com parâmetros otimizados assim:
> net.w
ans = -5.2017 0.8701 1.
> net.w
ans =
> net.b
ans = 2.4785 -0.6179 -0.
> net.b
ans = -0.
O quarto passo consiste em utilizarmos a rede recém treinada. Para isso utilizamos a função m lpfw d do Netlab, assim se quisermos saber qual seria a saída para a entrada x= 0. 565 , calculamos:
>mlpfwd(net,0.565)
ans = -0.
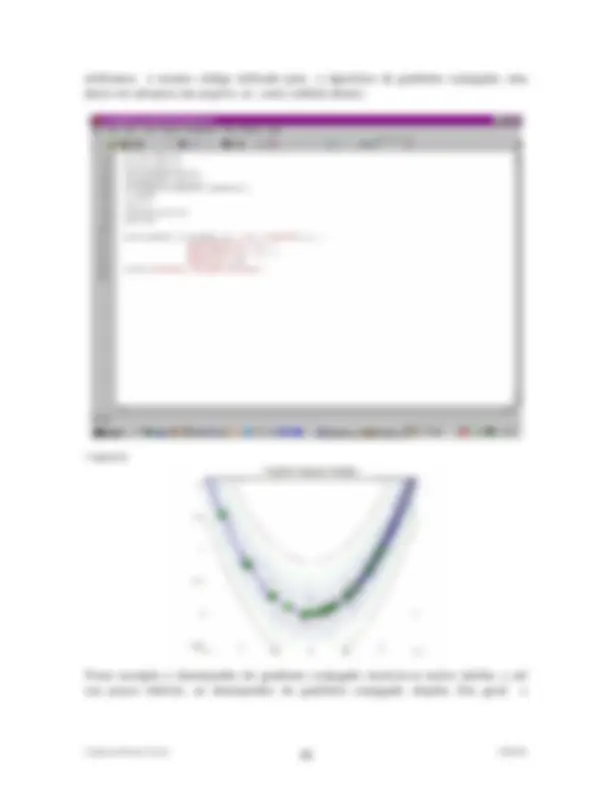
Para analisarmos visualmente a qualidade de nosso modelo para os dados representamso em um gráfico previsões para várias entradas e o valor "real":
9 plotvals=[0:0.01:1]'; 10 y=mlpfwd(net,plotvals); 11 plot(plotvals, y, 'ob',plotvals,sin(2piplotvals));
-1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
-0.
0
1
Na figura acima as previsões aparecem como circunferências e o valor "real" como uma linha cheia. A qualidade da previsão irá depender da Rede Neural empregada e do nível de ruído dos dados.
Algoritmos de Otimização
Aprendizado em Redes Neurais: Um Problema de Otimização
Como já dissemos, o problema de regressão utilizando Redes Neurais consiste em encontrar a função t ˆ^ = y ( , x w ) que produz melhores estimativas para a regra implícita
em um conjunto de exemplo de pares entrada-saída D = {( x (^ n )^^ , t (^ n^ ))} np = 1.
É importante ressaltar que a tarefa central de uma regressão não é a memorização do conjunto de exemplos D, mas sim a antecipação de pares novos (ou fora da amostra) que poderiam ser gerados pelo mesmo processo que gerou D.
A descrição completa do processo gerador do conjunto D é fornecida por uma densidade de probabilidade conjunta (^) p ( , ) x t sobre D. Esta densidade de probabilidade pode ser decomposta da seguinte forma: p ( , ) x t = p ( t x ) p ( ) x (1.1)
A densidade p ( t x )é conhecida como densidade condicional e representa a probabilidade
de uma saída t dada uma entrada com valor específico x. Já a densidade p( x ) representa a densidade incondicional de x que pode ser calculada a partir da densidade conjunta por integração (també conhecida como marginalização ):
p ( ) x = (^) ∫ p ( , t x ) d t (1.2)
Uma maneira pictórica de representarmos um modelo para o processo de geração do conjunto de dados D é exibida na figura a seguir:
No modelo acima há dois processos estocásticos: o de geração das entradas x descrito pela densidade p(x) e o de geração de saídas com ruído descrito pela densidade condicional p ( t x ).
Processo estocástico de geração de entradas x
Processo determinístico de geração de saídas y(x) ruído
Saídas corrompidas por ruído t
O aprendizado consiste em estimarmos a densidade condicional de probabilidade p ( t x )
que melhor se ajuste ao conjunto D, possibilitando assim a predição de saídas possíveis para entradas x fora do conjunto D utilizado no treinamento.
Ao modelarmos os dados utilizando Redes Neurais supomos uma arquitetura de rede, o que equivale à escolha de uma família de funções y ( ; x w ) parametrizada por w. Por
conseqüência a densidade condicional p ( t x w ; ) também é parametrizada por w. Para
encontrarmos qual é o vetor w que melhor ajusta os dados em D, podemos maximizar a função de verossimilhança definida por:
1
1
p n n n p n n n n
L p
p p
=
=
∏
∏
w x t w
t x w x
Alternativamente, e com uma série de vantagens práticas podemos definir uma função erro que deve ser minimizada no aprendizado:
1 1
( ) ln ( )
ln ( ; ) ln ( )
p p n n n n n
E L
p p = =
= − (^) ∑ −∑
w w
t x w x
O segundo somatório não depende do vetor de parâmetros w , podendo ser ignorado na minimização do erro E( w ):
1
( ) ln ( ; )
p n n
n
E p
w = − (^) ∑ t x w (1.5)
O aprendizado em uma Rede Neural consiste simplemente em uma tarefa de otimização: minimizar E( w ) dado o modelo o conjunto de treinamento D e a densidade condicional p ( t x w ; ).
Erro quadrático
Suponhamos que o processo real de produção de saídas t consista de uma perturbação estocástica ε sobre uma função determinística h( x ) assim:
t = h ( ) x + ε (1.6)
Suponhamos agora que a perturbação estocástica (ruído) seja distribuída de forma normal:
A escolha de diferentes valores para o parâmetro r regula a sensibilidade do modelo a valores com erros grandes, como pode ser visto na figura abaixo:
Conforme r aumenta maior é a penalização para desvios grandes que passam, por serem pouco prováveis, a ser considerados incompatíveis com os dados.
Exercícios
(1) Generalize (1.10) para o caso de saídas t multidimensionais. (2) Demonstre a expressão (1.12) para a função erro r-Minkowski.
Otimização
Há várias técnicas para otimização de funções multidimensionais e não-lineares como a função erro que devemos minimizar. Genericamente um algoritmo iterativo de otimização no espaço de parâmetros w consiste em uma busca onde a cada passo são determinados uma direção e um tamanho de passo:
w t (^) + 1 = w (^) t + α t d t (^) (1.13)
Quanto mais informação sobre a geometria da superfície definida pela função erro E(w) for utilizada mais eficiente será o algoritmo. Uma boa idéia de como um algoritmo de otimização pode utilizar a geometria da função erro pode ser obtida utilizando uma aproximação quadrática para a superfície. Consideremos a seguinte expansão em torno de um ponto w ˆ :
ˆ ˆ ˆ 1 ˆ ˆ ( ) ( ) ( ) ( ) ( ) ( ) 2
E w ≅ E w + w − w ⋅∇ E w + w − w ⋅ H w − w (1.14)
A matriz H é conhecida como Hessiano sendo definida como:
2
ˆ
jk j k
E
H
w w
∂ ∂ (^) w
Suponha que w ˆ^ = w * seja um extremo de E, então:
( ) ( *^ ) 1 ( *^ ) ( *) 2
E w ≅ E w + w − w ⋅ H w − w (1.16)
Podemos calcular os autovetores do Hessiano H : Hu k (^) = λ k u (^) k , (1.17)
onde u (^) j ⋅ u k (^) = δ jk. (1.18)
Podemos expandir o vetor w – w *^ na base dos autovetores de H para escrevermos:
k k k
w − w = (^) ∑ α u (1.19)
Substituindo (1.19) em (1.16) e utilizando (1.17) e (1.18) :
( ) ( *^ ) 1 2 (^2) k k^ k
E w ≅ E w + (^) ∑ λ α. (1.20)
Assim, os autovetores da Hessiana indicam direções ortogonais que diagonalizam a matriz H. De (1.20) pode-se concluir que para que w *^ defina um mínimo é necessário que todos os autovalores sejam positivos, além disso a velocidade de convergência do erro é maior em direções com autovalor maior.
Otimização em Netlab
Alternativamente, podemos utilizar a seguinte sintaxe menos direta:
1 x1=-2:0.01:2; 2 x2=-2:0.01:2; 3 [sx1, sx2] =meshgrid (x1,x2);
As instruções acima geram matrizes que contém o produto cartesiano dos vetores x1 e x2, assim se digitarmos
> [sx1(10,23) sx2(10,23)]
ans = -1.7800 -1.
Veremos um par específico de valores. A função de Rosenbrock pode ser calculada de duas formas:
> Y= 100*(sx1-sx2.^2).^2 +(1-sx1).^2; > size(Y)
ans = 401 401
onde utilizamos ".^ " com um ponto antes da operação para elevarmos cada componente das matrizes X1 e X2, sem "." teríamos calculado um produto matricial. Note que a resposta é uma discretização da superfície com 401 por 401 pontos.
Para exemplificar o cálculo com e sem ".":
> A=[0 1; 1 0]
A = 0 1 1 0
Um produto matricial será:
> A^
ans = 1 0 0 1 ou > A*A
ans = 1 0 0 1
Componente a componente teremos > A.^
ans = 0 1 1 0
Uma outra forma de avaliarmos a função de Rosenbrock é utilizarmos diretamente a função do Netlab chamada rosen: > Y1=rosen([sx1(:),sx2(:)]);
Esta operação retorna um vetor com 401 x 401 valores: > size(Y1)
ans = 160801 1
Este vetor pode então ser convertido em uma matrz com as dimensões apropriadas utilizando:
> (^) Y1=reshape(Y1,length(x1),length(x2));
Esta instrução converte um vetor em uma matriz com o número de linhas igual ao número de dimensões do vetor x1 (length(x1)) e o número de colunas igual ao número de dimensões do vetor x2 (length(x2)). A matriz é preenchida coluna a coluna conforme o exemplo a seguir:
> A=[1 2 3 4 5 6 7 8 9 10 11 12]; > A=reshape(A,4,3)
A = 1 5 9 2 6 10 3 7 11 4 8 12
Para plotarmos a superfície podemos utilizar a seguinte instrução : > surf(x1,x2,Y)
Podemos também plotar curvas de nível da superfície: > l=-1:6; >v=2.^l; >contour(x1,x2,Y,v)