



Tema 3
Estimaci´on puntual
Jos´e R. Berrendero
Departamento de Matem´aticas
Universidad Aut´onoma de Madrid
























Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Asignatura: Estadística, Profesor: José Berrendero, Carrera: Biología, Universidad: UAM
Tipo: Apuntes
1 / 32

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Jos´e R. Berrendero
Departamento de Matem´aticas Universidad Aut´onoma de Madrid
I (^) Estimaci´on de la media poblacional.
I (^) Estimaci´on de la proporci´on poblacional.
I (^) Sesgo, varianza y error cuadr´atico medio de un estimador.
I (^) M´etodos generales de obtenci´on de estimadores: I (^) M´etodo de momentos. I (^) M´etodo de m´axima verosimilitud.
Población
Observaciones
Densidad
0.0 0 2 4 6 8 10
0.^ 0.^ 0.^
n=
Medias
Frecuencia
0.0 0.5 1.0 1.5 2.0 2.5 3. 0
50
100
150
200
n=
Medias
Frecuencia
0.5 1.0 1.5 2. 0
50
100
150
200
250
300
n=
Medias
Frecuencia
0.6 0.8 1.0 1.2 1.4 1. 0
50
100
150
200
250
n=
Medias
Frecuencia
0.7 0.8 0.9 1.0 1.1 1.2 1.3 1. 0
50
100
150
200 lllll
l lll
l lll l
l lll
l lll lllllllllll lllllllllllllllll llllll l
l l n=5 n=10 n=50 n=
0.^ 1.^ 1.^ 2.^ 2.^
Comparación
Teorema central del l´ımite: Sea ¯x la media de una muestra de tama˜no n de una poblaci´on con media μ y desviaci´on t´ıpica σ. Entonces, si n es grande la distribuci´on de los valores que toma ¯x es aproximadamente normal de media μ y desviaci´on t´ıpica σ/
n
En notaci´on matem´atica, podemos escribir:
¯x ∼= N
μ, σ √ n
Si la poblaci´on de partida es normal, el resultado anterior es cierto de forma exacta para cualquier tama˜no muestral n.
I (^) El tiempo de espera de los estudiantes de la UAM hasta que llega el tren a la estaci´on de Cantoblanco es una variable aleatoria con distribuci´on exponencial de media 10 minutos. (a) Calcula la probabilidad de que un estudiante que llega a la estaci´on tenga que esperar entre 5 y 15 minutos. (b) Si se calcula el promedio de los tiempos de espera de 100 estudiantes (que llegan a la estaci´on en d´ıas y horas diferentes, de manera que los tiempos se pueden considerar independientes), calcula la probabilidad aproximada de que este promedio sea superior a 11 minutos. (c) Calcula la probabilidad aproximada de que, entre los 100 estudiantes del apartado anterior, haya m´as de 45 cuyo tiempo de espera est´e entre 5 y 15 minutos. I (^) El peso de los huevos producidos por una gallina tiene distribuci´on normal de media μ = 65 g y desviaci´on t´ıpica σ = 5 g. ¿Cu´al es la probabilidad de que una docena de huevos pese entre 750 y 825 g?
El error t´ıpico de un estimador es un estimador de su desviaci´on t´ıpica.
La desviaci´on t´ıpica de la media es σ/
n, pero en la pr´actica σ es un par´ametro poblacional desconocido.
Resulta natural estimar σ^2 con la cuasivarianza muestral:
S^2 = (x 1 − x¯)^2 + · · · + (xn − x¯)^2 n − 1
Se divide n − 1 ya que puede demostrarse que al dividir por n el estimador tiene una tendencia sistem´atica a infraestimar σ^2.
El error t´ıpico de la media muestral es
S √ n
I (^) Poblaci´on: Los 12 alumnos de una clase.
I (^) Variable: Nota que un alumno obtiene en un examen
Estudiante 1 2 3 4 5 6 7 8 9 10 11 12 Nota 1 0 3 10 8 7 5 5 5 6 4 3 Notas
x
Density
0.00 0 2 4 6 8 10
0.^ 0.^
I (^) Media poblacional:
μ =
I (^) Varianza poblacional:
σ^2 =
I (^) Desviaci´on t´ıpica poblacional:
σ =
I (^) Extraemos 2000 muestras de tama˜no 4. I (^) Todos los valores son equiprobables y se extraen con reemplazamiento (muestreo aleatorio simple). I (^) Un histograma de las correspondientes 2000 medias muestrales:
Medias
Frecuencias
2 4 6 8
0.^ 0.^ 0.^ 0.^
I (^) Las propiedades de ¯x como estimador de μ se corresponden con las propiedades del histograma anterior.
I (^) La forma del histograma es la de una distribuci´on normal.
I (^) Los valores de ¯x se centran alrededor del verdadero valor de μ. El estimador es centrado o insesgado.
I (^) La desviaci´on t´ıpica de ¯x es menor que σ. Se puede demostrar que la desviaci´on t´ıpica de ¯x es: σ √ n
I (^) Puede comprobarse que la varianza muestral (dividiendo por n) presenta una tendencia sistem´atica a infraestimar σ^2.
I (^) Para corregir este sesgo se incrementa ligeramente el valor del estimador dividiendo por n − 1 en lugar de n.
I (^) Diagramas de cajas de las 2000 varianzas y cuasivarianzas muestrales. La l´ınea roja corresponde a σ^2 = 7.3542.
lllllllllll lllll llllllll
l l
lll l
ll llllllllll l lllllllllll
lllll
llll
l llll
ll ll l l llllllll l
l
l
lll l
l ll l llll ll
lll l l ll llllll l
lll
l l
Dividir por n Dividir por n−
0
5
10
15
20
25
30
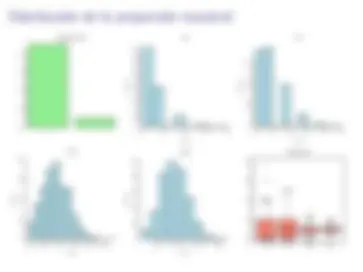
Queremos estimar la proporci´on p de personas en una poblaci´on que han seguido una dieta en los ´ultimos 5 a˜nos. Para ello, preguntamos a 10 personas y definimos
xi =
0 , si la persona i no ha seguido una dieta; 1 , si la persona i ha seguido una dieta.
Obtenemos los siguientes datos:
1 , 0 , 0 , 1 , 1 , 0 , 0 , 0 , 1 , 0
Estos datos son 10 observaciones de una v.a. de Bernoulli con par´ametro p.
¿Cu´al es el estimador m´as natural de p?
Seg´un el TCL, ¿c´omo se distribuye aproximadamente la proporci´on muestral ˆp?
¿Cu´al es la desviaci´on t´ıpica de ˆp?
¿Cu´al es el m´aximo (m´ınimo) valor posible de esta desviaci´on t´ıpica?
¿En qu´e situaci´on se va a dar ese valor?
En general, ¿cu´al es el error t´ıpico de ˆp?
Calcula el error t´ıpico de ˆp para los datos de la encuesta sobre la dieta.
Disponemos de una muestra aleatoria simple X 1 ,... , Xn de una v.a. X : I (^) Las observaciones X 1 ,... , Xn son independientes. I (^) Todas ellas tienen la misma distribuci´on que X
Se supone que la distribuci´on de X es conocida salvo por el valor de un conjunto de par´ametros que denotamos θ.
Objetivo: Aproximar el valor de θ a partir de la muestra. Para ello necesitamos calcular un estimador θˆ = ˆθ(X 1 ,... , Xn).
¿Que propiedades debe tener un buen estimador?
¿Existen m´etodos generales para obtener estimadores?