



Arthur Henrique Fernandes
Lara Tenore Ferreira
Matheus Eduardo dos Santos Araújo
Naími Moreira Nobre Leite
Rodrigo San Martin
Aprendizado de
Máquina
Projeto final
Música
Classificação








































Estude fácil! Tem muito documento disponível na Docsity

Ganhe pontos ajudando outros esrudantes ou compre um plano Premium

Prepare-se para as provas
Estude fácil! Tem muito documento disponível na Docsity
Prepare-se para as provas com trabalhos de outros alunos como você, aqui na Docsity
Encontra documentos específicos para os exames da tua universidade
Prepare-se com as videoaulas e exercícios resolvidos criados a partir da grade da sua Universidade
Responda perguntas de provas passadas e avalie sua preparação.
Ganhe pontos para baixar
Ganhe pontos ajudando outros esrudantes ou compre um plano Premium
Trabalho aprendizado de maquina
Tipologia: Trabalhos
1 / 58

Esta página não é visível na pré-visualização
Não perca as partes importantes!
Aprendizado de
Máquina
Projeto final
Música
Classificação
BASE DE DADOS - SPOTIFY_SONGS
playlist_genre
track_popularity
danceability
energy
key
loudness
mode
speechiness
acousticness
instrumentalness
valence
tempo
BASE DE DADOS - SPOTIFY_SONGS
Objetivo: Classificar músicas em gêneros a
partir dos seus parâmetros sonoros
Menos influenciado por outliers Colinearidade Reduz overfitting e variância
Porém: Alto custo computacional para muitas árvores
Limites de decisão complexos Estruturas de alta dimensão Alta acurácia
Rápido Múltiplas classes Variáveis categóricas
Porém: Assume que algumas características são independentes
Naive-Bayes
Porém: Ajuste mais difícil Não lida bem com outliers
Gradient
Boosting
ALGORITMOS
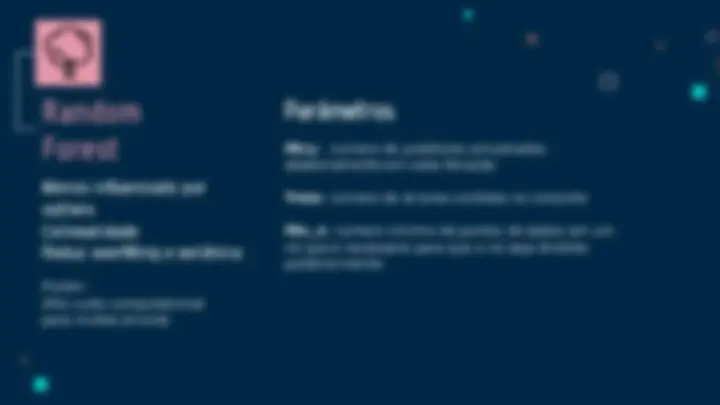
Random
Forest
Limites de decisão
complexos
Estruturas de alta
dimensão
Alta acurácia
Porém: Ajuste mais difícil Não lida bem com outliers
Gradient
Boosting
Learn_rate: taxa de adaptação a cada iteração para evitar o overfitting.
Trees: número de árvores contidas no conjunto
Min_n: número mínimo de pontos de dados em um nó que é necessário para que o nó seja dividido posteriormente
Tree_depth: profundidade máxima da árvore
Parâmetros
Xgboost (padrão), C5.0, spark
Engines
Menos influenciado por
outliers
Colinearidade
Reduz overfitting e variância
Porém: Alto custo computacional para muitas árvores
Random
Forest Mtry:^ número de preditores amostrados aleatoriamente em cada iteração
Trees: número de árvores contidas no conjunto
Min_n: número mínimo de pontos de dados em um nó que é necessário para que o nó seja dividido posteriormente
Parâmetros
AJUSTE DE PARÂMETROS - Naive-Bayes
AJUSTE DE PARÂMETROS - Gradiente Boosting
MÉTRICAS DE AVALIAÇÃO
MELHORES PARÂMETROS APÓS TUNING
Naive-Bayes
Smoothness - 0.
● Assume que as variáveis são independentes
● Quanto maior o smoothness, mais subajustado e mais viés
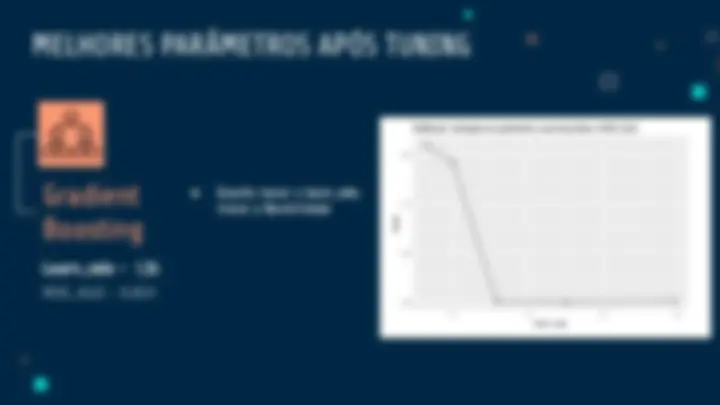
MELHORES PARÂMETROS APÓS TUNING
Mtry - entre 2 e 5
ROC_AUC - entre 0, e 0,
Random
Forest
● Quanto maior o Mtry, maior a taxa de sobreajuste
● Quanto menor o Mtry, mais variância.
CONCLUSÃO
Naive-Bayes
ROC_AUC - 0.
Gradient Boosting ROC_AUC - 0.
Random Forest ROC_AUC - 0.
3º
2º
1º
Os dois algoritmos de árvore performaram acima do Naïve Bayes para o presente conjunto de dados.
XGBoost apresenta uma dificuldade de ajuste de parâmetros
Concluímos que, para este conjunto de dados, o Random Forest é o melhor algoritmo dentre os testados.
Here’s what you’ll find in this Slidesgo template:
1. A slide structure based on a consulting sales pitch, which you can easily adapt to your needs. For more info on how to edit the template, please visit Slidesgo School or read our FAQs. 2. An assortment of illustrations that are suitable for use in the presentation can be found in the alternative resources slide. 3. A thanks slide, which you must keep so that proper credits for our design are given. 4. A resources slide, where you’ll find links to all the elements used in the template. 5. Instructions for use. 6. Final slides with: ● The fonts and colors used in the template. ● More infographic resources , whose size and color can be edited. ● Sets of customizable icons of the following themes: general, business, avatar, creative process, education, help & support, medical, nature, performing arts, SEO & marketing, and teamwork.
You can delete this slide when you’re done editing the presentation.
CONTENTS OF THIS TEMPLATE
TARGET Here you could describe the topic of the section
OUR PROCESS
PROBLEM & SOLUTION Here you could describe the topic of the section
01
Here you could describe the topic of the section
02
TABLE OF CONTENTS
03