Download Overlapped - High Performance Computing - Lecture Slides and more Slides Computer Science in PDF only on Docsity!
High Performance Computing
Lecture 10
2
We will assume that …
1. Activity is overlapped in time where possible
- PC increment and instruction fetch from memory?
- Instruction decode and effective address calculation
2. Load-store ISA: the only instructions that take
operands from memory are loads & stores
3. Main memory delays are not typically seen by the
processor
- Otherwise the timeline is dominated by them
- There is some hardware mechanism through which most memory access requests can be satisfied at processor speeds (cache memory)
4
Steps in Instruction Execution
Fetch instruction from memory to processor
- IR = Memory[PC]
- Increment PC
Decode instruction and get its operands
- Decode
- Get Operands from registers
Execute the operation
- Trigger appropriate functional hardware
- Load/store: get data from main memory
Write back the result
- Write result to destination register cache memory access (simple) ALU operation (simple) logic circuitry register access cache access register access ALU operation
5
Unit of timescale of processor; time required to do a
basic operation
Cache memory access Register access + some logic (like decode) ALU operation
Term: Processor Cycle Time
7
Steps in Execution: JR R
Fetch instruction from memory to processor
- IR = Memory[PC]; Increment PC
Decode instruction and get its operands
- Decode; Get Operands from registers
Execute the operation
- Trigger appropriate functional hardware
- Load/store: get data from main memory
Write back the result
- Write result to destination register 1 cycle 1 cycle 1 cycle 1 cycle 1 cycle
8
Steps in Execution: ADD R1, R2, R
Fetch instruction from memory to processor
- IR = Memory[PC]; Increment PC
Decode instruction and get its operands
- Decode; Get Operands from registers
Execute the operation
- Trigger appropriate functional hardware
- Load/store: get data from main memory
Write back the result
- Write result to destination register 1 cycle 1 cycle 1 cycle 1 cycle 1 cycle
10
Unit of timescale of processor; time required to do a
basic operation
Cache memory access Register access + some logic (like decode) ALU operation
A MIPS 1 instruction can be processed in 3-5 cycles
Jump: IFetch, Decode/OpFetch, DoOp (3) ALU: IFetch, Decode/OpFetch, DoOp, WriteReg (4) Load: IFetch, Decode, EffAddr, Cache, WriteReg (5)
Addressing modes: (R) vs d(R)
Term: Processor Cycle Time
11
Instruction Execution
Mem IR
PC NPC
Instruction Fetch (IF)
from program memory to instruction register IR Mem [PC] Increment PC Instr Fetch
13
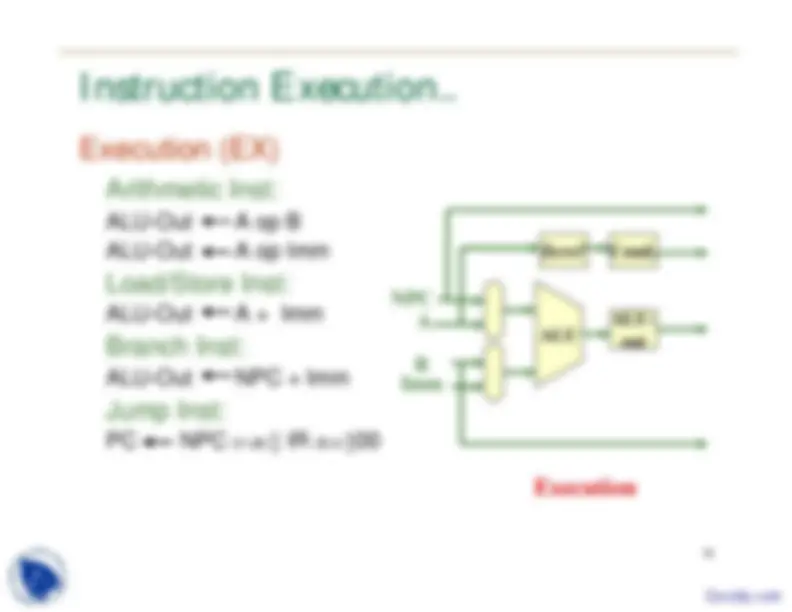
Instruction Execution..
Execution (EX)
Arithmetic Inst:
ALU-Out A op B ALU-Out A op Imm
Load/Store Inst:
ALU-Out A + Imm
Branch Inst:
ALU-Out NPC + Imm
Jump Inst:
PC NPC 31 - 28 || IR 25 - 0 || Imm NPC ALU- out ALU Zero? B A Cond. Execution
14
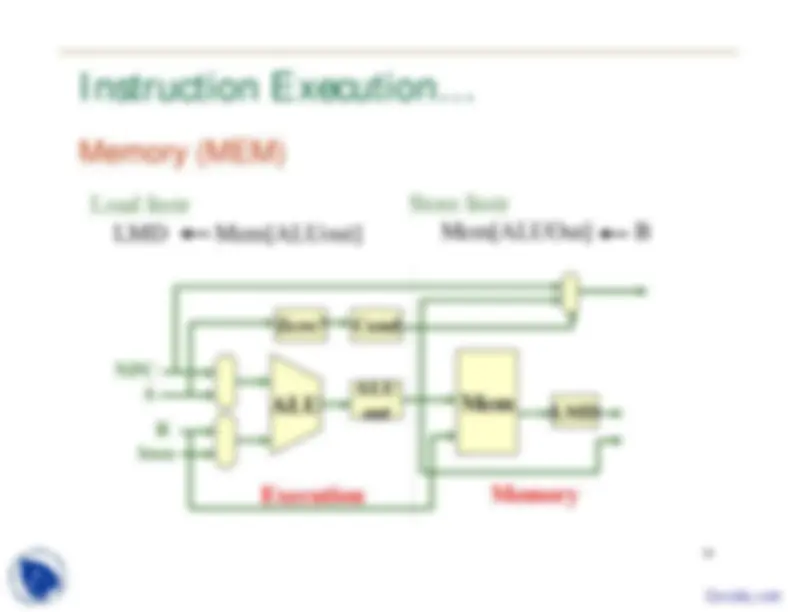
Instruction Execution…
Memory (MEM)
Execution Memory Imm NPC ALU out
ALU
Zero? Mem LMD B A Cond Store Instr Mem[ALUOut] B Load Instr LMD Mem[ALUout]
16
Inside the Processor
Mem IR
PC NPC Reg File sign extend A Imm B Inst Fetch IF Inst Decode ID 4 ALU ALU out Zero? Mem LMD Execution EX Memory MEM Cond WB
17
Reality Check
Problem: There could be many programs
running on a machine concurrently
Sharing the resources of the computer
Processor time
Main memory
They must be protected from each other
One program should not be able to access the
variables of another
This is typically done through Address Translation
19
Idea of Address Translation
Each program is compiled to use addresses in the
range 0 .. MaxAddress (e.g., 0 .. 2
32
These addresses are not real, but only Virtual
Addresses
They have to be translated into actual main memory
addresses
The translation can be done to ensure that one
program can not access variables of another program
Many programs in execution can then safely share
main memory
Terminology: virtual address, physical address
Memory Management Unit (MMU): The hardware that
does the address translation
20
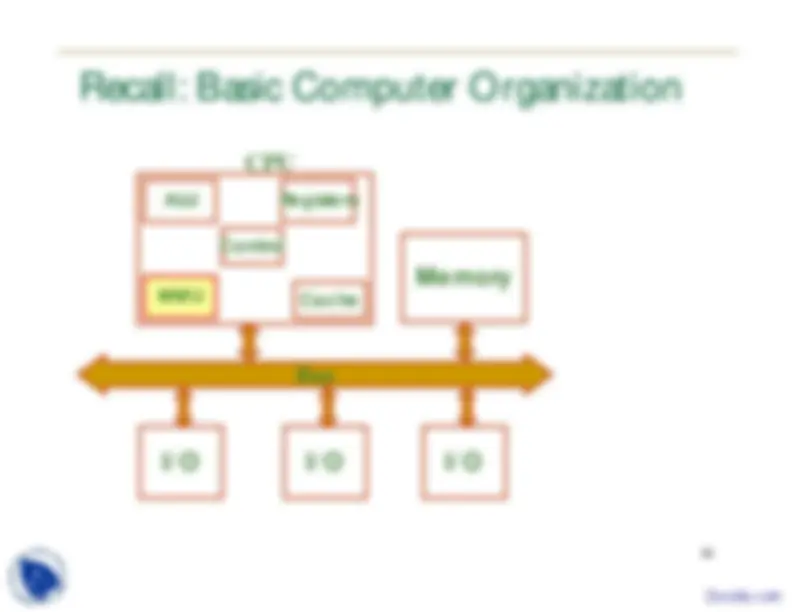
Recall: Basic Computer Organization
Cache Memory I/O Bus I/O I/O MMU ALU Registers
CPU
Control