



BIOMETRICS
INFORMATION
HANDBOOK NO. 4 MARCH 1994
Catalog of Curves
for Curve Fitting
Biometrics Information Handbook Series
Province of British Columbia
Ministry of Forests




























































































Estude fácil! Tem muito documento disponível na Docsity

Ganhe pontos ajudando outros esrudantes ou compre um plano Premium

Prepare-se para as provas
Estude fácil! Tem muito documento disponível na Docsity
Prepare-se para as provas com trabalhos de outros alunos como você, aqui na Docsity
Encontra documentos específicos para os exames da tua universidade
Prepare-se com as videoaulas e exercícios resolvidos criados a partir da grade da sua Universidade
Responda perguntas de provas passadas e avalie sua preparação.
Ganhe pontos para baixar
Ganhe pontos ajudando outros esrudantes ou compre um plano Premium
Este documento fornece informações sobre como estimar modelos de curvas usando o sas, incluindo as equações, derivadas e formas linearizadas. Discutimos o método de menos quadrados e máximo likelihood, além de fornecer exemplos de programas sas. O documento também aborda a convergência e como determinar os parâmetros iniciais.
Tipologia: Notas de estudo
1 / 116

Esta página não é visível na pré-visualização
Não perca as partes importantes!
Province of British Columbia Ministry of Forests
CATALOGUE OF CURVES
FOR CURVE FITTING
by Vera Sit Melanie Poulin-Costello
Series Editors Wendy Bergerud Vera Sit
Ministry of Forests Research Program
iii
The authors would like to thank all the reviewers for their valuable comments. Special thanks go to Jeff Stone, Jim Goudie, and Gordon Nigh for their suggestions to make this handbook more comprehensive. We also want to thank Amanda Nemec and Hong Gao for checking all the derivatives and graphs in this handbook.
This handbook is a collection of linear and non-linear models for fitting experimental data. It is intended to help researchers fit appropriate curves to their data.
Curve fitting, also known as regression analysis, is a common technique for modelling data. The simplest use of a regression model is to summarize the observed relationships in a particular set of data. More importantly, regression models are developed to describe the physical, chemical and biological processes in a system (Rawlings 1988).
This handbook is organized in the following manner:
This handbook does not provide an in-depth discussion of regression analysis. Rather, it should be used in conjunction with a reliable text on linear and non-linear regression such as Ratkowsky (1983) or Rawlings (1988).
In regression, a model or a mathematical equation is developed to describe the behaviour of a variable of interest. The variable may be the growth rate of a tree, body weight of a grizzly bear, abundance of fish, or percent cover of vegetation. This is called the dependent variable and is denoted by Y. Other variables that are thought to provide information on the behaviour of the dependent variable are incorporated into the equation as explanatory variables. These variables (e.g., seedling diameter, chest size of a grizzly bear, volume of cover provided by large woody debris in streams, or light intensity) are called independent variables and are denoted by X. They are assumed to be known without error.
In addition to the independent variables, a regression equation also involves unknown coefficients called parameters that define the behaviour of the model. Parameters are denoted by lowercase letters (a, b, c, etc). A response curve (or ‘‘response surface’’, when many independent variables are involved) represents the true relationship between the dependent and independent variables. In regression analysis, a model is developed to approximate this response curve — a process that estimates parameters from the available data. A regression model has the general form:
Y = ƒ (X) + E
where ƒ (X) is the expected model and E is the error term. For simplicity, the error term E is omitted in subsequent sections.
A linear model is one that is linear in the parameters — that is, each term in the model contains only one parameter which is a multiplicative constant of the independent variable (Rawlings 1988, p. 374). All other models are non-linear. For example:
Y = a X + b
and Y = c X^2 + d X + g
are linear models with parameters a and b , and c , d , and g , respectively. But:
Y = a Xb
and Y = a sin(bX)
are non-linear models.
Some non-linear models are intrinsically linear. This means they can be made linear with an appropriate transformation. For example, the model:
Y = a e bx
is intrinsically linear. It can be converted to linear form with the natural logarithm (ln) transform:
ln(Y) = ln(a) + b X
However, some non-linear models cannot be linearized. The model:
Y = sin(bX)
is an example.
Linear models are very restrictive and are usually used for first-order approximations to true relationships. On the other hand, non-linear models such as the inverse polynomial models, exponential growth models, logistic model and Gompertz model, are often more realistic and flexible. In some cases, non-linear models will have fewer parameters to be estimated and are therefore simpler than linear models.
Once a curve or model has been fitted (i.e., the parameters are estimated) to a set of data, it can be used to estimate Y for each value of X. The deviation or difference of the observed Y from its estimate is called a residual. It is a measure of the agreement between the model and the data.
The parameters in a model can be estimated by the least squares method or the maximum likelihood method. With the least squares method the fitted model should have the smallest possible sum of squared residuals, while with the maximum likelihood method the estimated parameters should maximize the likelihood of obtaining the particular sample. Under the usual assumptions that the residuals are independent with zero mean and common variance σ^2 , the least squares estimators will be the best (minimum variance) among all possible linear unbiased estimators. When the normality assumption is satisfied, least squares estimators are also maximum likelihood estimators.
use the least squares method for estimating the model parameters.
or Z = c + b U
must be performed in a data step. If the variables Y and X were stored in a SAS data set called OLD, then the following SAS code^1 could be used to do the regression:
Once the regression is completed, the fitted parameters can be transformed to the parameters in the non- linear model. Continuing with the example, the parameter a in the non-linear model can be obtained from the intercept of the fitted linear model with the exponential function:
a = e c
Parameter b has the same value in both the linear and non-linear model.
fitted regression model is:
ln(Y) = ln(a) + b ln(X) + E (1)
The error term E in this model is additive. When the model is transformed back to its non-linear form, it becomes:
Y = a X b^ ⋅ e E^ (2)
the model:
Y = a X b^ + E (3)
If E in the linear model (1) is normally distributed, then e E^ in the non-linear model (2) is log-normal distributed, which is different from the normal distribution assumed in the non-linear model (3). Because of the different error structures in models (2) and (3), different parameter estimates may result. An example is given in Section 5.6.
In this handbook, the linearized forms, the relationships between parameters in the linear and non-linear forms, and the SAS programs for fitting the linearized models are provided for all intrinsically linear models.
Non-linear models are more difficult to specify and estimate than linear models. In SAS, they can be fitted with
names, guess the starting values of the parameters, and possibly specify the derivatives of the model with
(^1) In SAS, the function LOG is the natural logarithm (ln). Logarithm to the base 10 can be requested by the SAS function LOG10.
When derivatives are provided, the Gauss-Newton is the default method of estimation; otherwise, DUD is the default method. Of the two default methods, the Gauss-Newton method is fastest.
a set of data. The following is an example to carry out the regression:
created SAS data set is used.
Other options are available to control the iteration process. See Chapter 23 of the SAS/STAT User’s Guide (SAS Institute Inc. 1988a) for more detail.
A range of starting values may also be specified with this statement. For example:
specifies four starting values (0, 5, 10, and 15) for A.
specifies three starting values (1, 7, and 9).
Guide (SAS Institute Inc. 1988a) for more details.
The expression can be any valid SAS expression.
The functional form is the equation of the model. It is stated as:
Y = ƒ(X)
Standard functional names are used if possible. Otherwise, the functions are named sequentially as Type I or
a curve such as the maximum, minimum, and point of inflection. These features and the technique to identify
For intrinsically linear models, the linearized form and the relationship between the parameters in the linear and non-linear forms are supplied. Also included is a short description of the curve and the roles the parameters play in determining the behaviour of the curve. Sample SAS programs for doing linear or non- linear regression are provided for readers’ convenience. To use these programs, the X’s and Y’s should be replaced by the appropriate variable names. In addition, appropriate starting values must be substituted if
Finally, a number of graphs are presented for each curve. Each graph shows the impact of changing a parameter on the curve when other parameters are kept constant. These graphs are helpful for selecting models and parameter starting values.
The domain of a function is the set of X-values for which the function is defined. For most of the models presented in this section, the domain is the set of real numbers: − ∞ < X < ∞.
4.1 Polynomials
A polynomial of degree n has the form:
Y = c 0 + c 1 X + c 2 X^2 + … + cn − 1 Xn^ −^1 + c (^) n Xn
where the c (^) i’s are real numbers. They are the parameters , or coefficients , of the X terms. For example:
is a polynomial of degree 2 with parameters c 0 = 1, c 1 = 5, and c 2 = 2. The equation:
is a polynomial of degree 3 with parameters c 0 = c 1 = c 2 = 0 and c 3 = 4.
Polynomials are unbounded — that is, as X increases indefinitely, the function Y increases or decreases without limit.
A criterion for selecting a functional form is the number of extremums (i.e., maximum or minimum or both). A polynomial of degree n has at most n-1 extremums. For example, equation (1) is a polynomial of degree 2 with one minimum; equation (2) is a polynomial of degree 3 with no extremum. A polynomial of degree 1 is a straight line with no extremum.
Polynomials are a common choice for curve fitting because they are simple to use. Lower degree polynomials are easier to interpret than higher degree polynomials. For this reason, only polynomials of degree one, two, and three are included here. Although polynomials can provide a very good fit to data, they extrapolate poorly and should be used with caution.
Any continuous response function can be approximated to any level of precision desired by a polynomial of appropriate degree. Because of this flexibility, it is easy to ‘‘overfit’’ a set of data with polynomial models. Thus, an excellent fit of a polynomial model (or for that matter, any model) cannot be interpreted as an indication that it is, in fact, the true model.
4.1.1 First degree polynomial: linear
Functional form: Y = a + bX − ∞ < X < ∞
Derivatives: dY dX
= b
∂a ∂b
Linearized model and parameters: This functional form is already linear.
Description: This is the equation of a straight line. Parameter a is the Y-intercept and it controls the vertical position of the line. Parameter b is the slope of the line.
Functional form: Y = A(X − B) 2 + C
4.1.3 Third degree polynomial: cubic
Functional form: Y = a + bX + cX 2 + dX 3 − ∞ < X < ∞
Derivatives: dY dX
= b + 2cX + 3dX 2
∂a ∂b ∂c ∂d
Linearized model and parameters: This functional form is already linear.
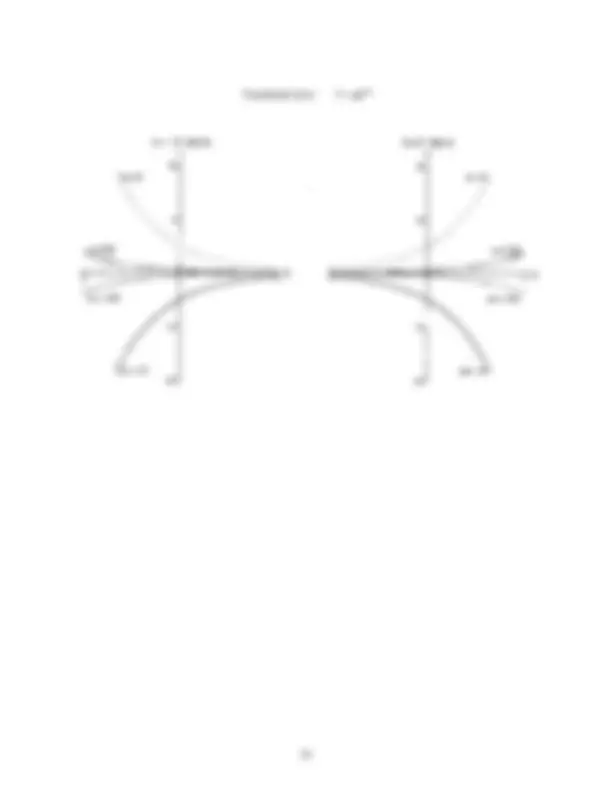
Description: The basic shape of a cubic is a sideways ‘‘S’’ ( ). Parameter d shifts the curve up and down the Y-axis. The parameters a , b , and c work together to make the S-shape flatter or deeper. While the above form is linear, the role of the parameters is more clearly understood in the alternative form:
Y = A (X − B) (X − C) (^) ( X^ −^
2 )^ +^ D
The parameters in the two forms are related as follows:
a = D − ABC (^) ( B^ +^ C^ ) b = A (B^ +^ C)^
2
c = −^3 A (B + C) d = A 2
Also A = d B = (^1) [ − 2c^ + √
4c^2 − 4 ( b^ −^
2c 2 2 3d 9d^2 d 9d ) ]
C = (^1) [ − 2c^ − √
4c^2 − 4 ( b^ −^
2c 2 2 3d 9d^2 d 9d) ]
D = a − c^ ( b − 2c^
2 3d 9d)
In the non-linear form of the cubic, parameter A scales the curve in the Y direction and D shifts the curve in the Y direction. Parameters B and C have the same effects on the shape of the curve; together they shift and squeeze the curve in the X direction. As parameters B and C are equivalent, only the graphs that show the effect of varying B are presented in the following pages.