



















































































Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Asignatura: Econometria, Profesor: , Carrera: Administración y dirección de empresas, Universidad: UJAEN
Tipo: Apuntes
1 / 88

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
(BASADO EN LOS APUNTES DE ANTONIO CONDE SÁNCHEZ)
Técnica estadística que consiste en buscar la mejor función que exprese la relación existente entre dos o más variables.
Y variable dependiente (endógena) X variable independiente (exógena)
Técnica estadística que consiste en buscar la mejor función LINEAL o recta que exprese la relación existente entre dos o más variables.
Es un modelo que explica la relación existente entre una variable dependiente o variable endógena y varias variables independientes o exógenas mediante una función lineal:
Y = β 0 + β 1 X 1 + β 2 X 2 + ... + β k Xk + u
escribirse como:
(Y X (^) i , (^1) i, …, Xki)
Yi = β 0 + β 1 X 1 i + β 2 X 2 i + ... + βk Xki + ui i =1,...,n
Otra forma de expresar el modelo es utilizando notación matricial:
donde
1 11 1 0 1 2 12 2 1 2
1
1 1 ; ; ;
1
k k
n n kn k n
Y X X u Y X X u
Y X X u
β β
β
(^) … … = (^) = (^) = (^) = …
y X β u
Consecuencias e interpretación de las hipótesis
componentes:
Uno determinista, que es su valor medio X β. Y otro aleatorio, que es u.
( )
y Xβ In
casi siempre alguna relación (no son incorreladas), no miden los
Cuando la relación entre las variables exógenas es pequeña, la mezcla es poco importante, pero si la relación es fuerte, los coeficientes tienden a ser menos precisos y no expresan los
β (^) j , j = 0,1,...,k β^ ˆ , (^) j j = 0,1,..., k.
¿Se ajusta bien la ecuación a los datos? ¿Es válido el modelo? ¿Tienen un efecto significativo las
¿Es útil el modelo como predictor? ¿Se viola alguna de las hipótesis básicas?
Por lo que la suma de los residuos al cuadrado es:
S = ˆ ˆ u u ′^^ = y y ′^ − 2 β X y^ ˆ′^ ′^ + β X Xβ ˆ′^ ′ ˆ
Derivando e igualando a 0 se obtienen las ecuaciones normales de regresión:
Despejando, obtenemos los estimadores MCO de los parámetros:
X y ′^ = X X ′ β^ ˆ
( ) ˆ −^1 β = X X ′^ X y ′
siempre y cuando exista la matriz. Dicha matriz existe si las variables explicativas son linealmente independientes (hipótesis 7).
( )
− 1 X X ′
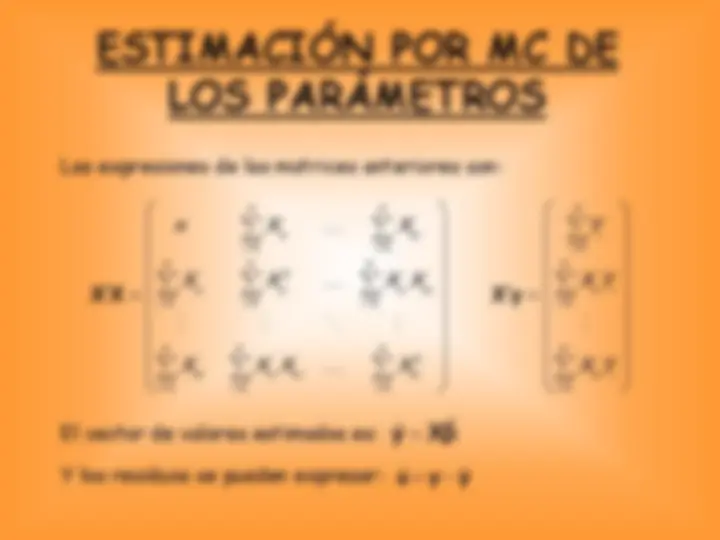
Las expresiones de las matrices anteriores son:
1 1 1 1 2 1 1 1 1 1 1 1 1
2 1 1 1 1 1
n n n i ki i i i i n n n n i i i ki i i i i i i
n n n n ki i ki ki ki i i i i i
n X X Y
X X X X X Y
X X X X X Y
= = =
= = = =
= = = =
∑ ∑ ∑
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
X X X y
Y los residuos se pueden expresar: (^) u ˆ^ = y − y ˆ
Obtenemos las matrices:
Interpretación de los coeficientes de regresión:
n i i
∑ =
Esto significa que: 1 1
n n i i i i
= =
∑ =^ ∑ ⇒^ =
1
ˆ (^) 0, 1, ,
n ji i i
∑ =^ =^ …
1
ˆˆ (^0)
n i i i
∑ =